This workflow corresponds to n8n.io template #11489 — we link there as the canonical source.
This workflow follows the Agent → Google Sheets recipe pattern — see all workflows that pair these two integrations.
The workflow JSON
Copy or download the full n8n JSON below. Paste it into a new n8n workflow, add your credentials, activate. Full import guide →
{
"id": "4CACq4vzjqUWBrPb",
"meta": {
"templateCredsSetupCompleted": true
},
"name": "LLM-Driven Review Summary & KPI Extractor",
"tags": [],
"nodes": [
{
"id": "e9618bd5-5db4-4b2c-9b16-41e757e7c818",
"name": "When clicking \u2018Execute workflow\u2019",
"type": "n8n-nodes-base.manualTrigger",
"position": [
464,
576
],
"parameters": {},
"typeVersion": 1
},
{
"id": "f3b60314-8e02-4a3a-b08f-78ea2a7becf1",
"name": "Code in JavaScript",
"type": "n8n-nodes-base.code",
"position": [
1504,
352
],
"parameters": {
"jsCode": "function htmlToText(html) {\n if (!html || typeof html !== \"string\") return \"\";\n\n let text = html;\n\n text = text.replace(/<script[\\s\\S]*?<\\/script>/gi, \"\");\n text = text.replace(/<style[\\s\\S]*?<\\/style>/gi, \"\");\n\n text = text.replace(/<\\/(p|div|section|article|li|tr|h1|h2|h3|h4|h5|h6)>/gi, \"\\n\");\n text = text.replace(/<br\\s*\\/?>/gi, \"\\n\");\n\n text = text.replace(/<\\/?[^>]+>/g, \"\");\n\n text = text\n .replace(/ /gi, \" \")\n .replace(/&/gi, \"&\")\n .replace(/"/gi, \"\\\"\")\n .replace(/'/gi, \"'\")\n .replace(/</gi, \"<\")\n .replace(/>/gi, \">\");\n\n text = text\n .split(\"\\n\")\n .map(line => line.trim())\n .filter(Boolean)\n .join(\"\\n\");\n\n return text;\n}\n\nfunction getDomain(url) {\n try {\n const u = new URL(url);\n return u.hostname.replace(/^www\\./, \"\");\n } catch (e) {\n return \"\";\n }\n}\n\nfunction extractTag(html, tag) {\n if (!html) return \"\";\n const regex = new RegExp(`<${tag}[^>]*>([\\\\s\\\\S]*?)<\\\\/${tag}>`, \"i\");\n const match = html.match(regex);\n return match ? String(match[1]).trim() : \"\";\n}\n\nfunction cleanEntityName(text) {\n if (!text) return \"\";\n return String(text)\n .replace(/reviews?/gi, \"\")\n .replace(/read customer service/gi, \"\")\n .replace(/customer service/gi, \"\")\n .replace(/\\|.*$/g, \"\")\n .replace(/-.*$/g, \"\")\n .replace(/\\s+/g, \" \")\n .trim();\n}\n\n// NEW: extract slug from Trustpilot-like URL\nfunction extractEntitySlugFromUrl(url) {\n if (!url) return \"\";\n try {\n const u = new URL(url);\n // Example path: /review/maclear.ch\n const parts = u.pathname.split(\"/\").filter(Boolean); // [\"review\",\"maclear.ch\"]\n const reviewIdx = parts.findIndex(p => p.toLowerCase() === \"review\");\n if (reviewIdx >= 0 && parts[reviewIdx + 1]) {\n return parts[reviewIdx + 1].trim();\n }\n // Generic fallback: last path segment\n return (parts[parts.length - 1] || \"\").trim();\n } catch (e) {\n // If it's not a valid URL string\n const m = String(url).match(/\\/review\\/([^/?#]+)/i);\n return m ? m[1].trim() : \"\";\n }\n}\n\nconst newItems = [];\n\nfor (const item of items) {\n const json = item.json || {};\n let result = json;\n\n // If wrapped in { results: [ ... ] }, extract first result\n if (Array.isArray(json.results) && json.results.length > 0) {\n result = json.results[0];\n }\n\n // URL can come from different places depending on your node\n const url = result.url || json.url || \"\";\n const html = result.content || result.html || \"\";\n\n const pageText = htmlToText(html);\n const domain = getDomain(url);\n\n // Trustpilot-like slug: maclear.ch / apify.com\n const entitySlug = extractEntitySlugFromUrl(url) || null;\n\n // Prefer h1/title, but fallback to slug if extraction is messy\n const h1Text = extractTag(html, \"h1\");\n const titleText = extractTag(html, \"title\");\n const extractedName = cleanEntityName(h1Text || titleText);\n\n const entityName = extractedName\n ? extractedName\n : (entitySlug ? entitySlug : null);\n\n newItems.push({\n json: {\n url,\n domain,\n entity_slug: entitySlug,\n entity_name: entityName,\n page_text: pageText,\n raw_html_length: html.length\n }\n });\n}\n\nreturn newItems;\n"
},
"typeVersion": 2
},
{
"id": "bab39db3-d0d7-422e-aff9-075909f6dd00",
"name": "AI Agent",
"type": "@n8n/n8n-nodes-langchain.agent",
"position": [
1728,
352
],
"parameters": {
"text": "=You are given the cleaned text of a review page.\n\nMetadata:\n- URL: {{ $json[\"url\"] || \"\" }}\n- Domain: {{ $json[\"domain\"] || \"\" }}\n\nFull page text:\n\"\"\"\n{{ $json[\"page_text\"] || \"\" }}\n\"\"\"\n\nFrom this text, you must infer as many reviews as possible and then return ONLY a single JSON object with the following structure:\n\n{\n \"source_url\": \"\",\n \"source_domain\": \"\",\n \"estimated_total_reviews\": 0,\n \"average_rating\": null,\n \"rating_scale_max\": 5,\n \"rating_distribution\": {\n \"1\": 0,\n \"2\": 0,\n \"3\": 0,\n \"4\": 0,\n \"5\": 0\n },\n \"sentiment_distribution\": {\n \"positive\": 0,\n \"neutral\": 0,\n \"negative\": 0\n },\n \"top_positive_keywords\": [],\n \"top_negative_keywords\": [],\n \"top_praises\": [],\n \"top_complaints\": [],\n \"topic_distribution\": {\n \"pricing\": 0,\n \"usability\": 0,\n \"features\": 0,\n \"support\": 0,\n \"performance\": 0,\n \"other\": 0\n },\n \"recent_trend_summary\": \"\",\n \"data_quality_notes\": \"\"\n}\n\nField definitions and instructions:\n\n- \"source_url\":\n - Copy exactly the URL provided.\n\n- \"source_domain\":\n - Copy exactly the domain provided.\n\n- \"estimated_total_reviews\":\n - Your best estimate of how many individual reviews are present in the text.\n - If unclear, use 0.\n\n- \"average_rating\":\n - The average rating across all detected reviews.\n - Use a numeric value like 4.3 if there is enough information.\n - If no rating information is reliably available, use null.\n\n- \"rating_scale_max\":\n - The maximum rating scale observed or assumed (usually 5).\n - If unclear, default to 5.\n\n- \"rating_distribution\":\n - Number of reviews that fall into each star bucket (1\u20135).\n - If you detect a different scale (e.g., 1\u201310), still try to map to 1\u20135 as best as possible.\n - If information is unclear, keep values as 0.\n\n- \"sentiment_distribution\":\n - Number of reviews that are overall positive, neutral, or negative based on the text.\n - If you have no signal at all, use 0 for all three.\n\n- \"top_positive_keywords\":\n - Array of short keywords or phrases frequently mentioned in positive reviews.\n - Examples: [\"easy to use\", \"great support\", \"fast\", \"intuitive interface\"]\n - Maximum 10 entries.\n\n- \"top_negative_keywords\":\n - Array of short keywords or phrases frequently mentioned in negative reviews.\n - Examples: [\"too expensive\", \"bugs\", \"slow performance\", \"poor support\"]\n - Maximum 10 entries.\n\n- \"top_praises\":\n - Short bullet-style sentences summarizing what customers like the most.\n - Example: \"Users appreciate how easy it is to get started.\"\n - 3 to 7 items.\n\n- \"top_complaints\":\n - Short bullet-style sentences summarizing the main pain points or complaints.\n - Example: \"Several users complain about slow response times from support.\"\n - 3 to 7 items.\n\n- \"topic_distribution\":\n - A rough count of how many reviews mention each topic:\n - \"pricing\"\n - \"usability\"\n - \"features\"\n - \"support\"\n - \"performance\"\n - \"other\"\n - Use integer counts. If something is unclear, leave it as 0.\n\n- \"recent_trend_summary\":\n - A short paragraph (3\u20135 lines) describing:\n - overall tone (improving, stable, deteriorating)\n - any shifts in sentiment or recurring issues\n - anything noteworthy for a product / CX team.\n\n- \"data_quality_notes\":\n - Explain briefly any limitations:\n - e.g., \"Only a small subset of reviews is visible.\"\n - \"Ratings are not explicitly shown, so rating distribution is approximate.\"\n - \"Some reviews appear duplicated.\"\n\nVERY IMPORTANT:\n- If something is unclear or not available, do NOT invent precise numbers.\n- Use conservative estimates or 0/null/empty lists.\n- Return ONLY the JSON object, with no extra commentary, no markdown and no backticks.\n",
"options": {
"systemMessage": "You are an AI assistant specialized in analyzing customer reviews and generating aggregated metrics.\n\nYou will receive the cleaned text content of one or more review pages (from platforms like G2, Capterra, Trustpilot, Amazon, Google Play, etc.). The text may be noisy, but it will contain multiple customer reviews, ratings, dates, and comments.\n\nYour job is to:\n- Detect and infer individual reviews from the text (as best as possible).\n- Aggregate the information.\n- Return ONLY a single JSON object with high-level metrics about these reviews.\n\nYou MUST:\n- Follow the JSON schema provided in the user instructions exactly.\n- Return ONLY a valid JSON object, with no extra text, no explanations, and no markdown.\n- Be conservative with assumptions: if something is unclear, use null, 0, or an empty array.\n- Focus on metrics that are useful for product, marketing, and CX teams (quality, sentiment, themes, trends)."
},
"promptType": "define"
},
"typeVersion": 3
},
{
"id": "be657b0c-23e1-4b8c-bd25-9915a5947358",
"name": "Code in JavaScript1",
"type": "n8n-nodes-base.code",
"position": [
2080,
352
],
"parameters": {
"jsCode": "// This Function node takes the LLM \"output\" field (JSON string),\n// parses it, and flattens it into a structure ready to be saved\n// into Google Sheets (one row per item).\n\nconst newItems = [];\n\nfor (const item of items) {\n const rawOutput = item.json.output;\n\n let parsed;\n if (typeof rawOutput === 'string') {\n try {\n parsed = JSON.parse(rawOutput);\n } catch (error) {\n // If parsing fails, keep debug info\n newItems.push({\n json: {\n parse_error: true,\n error_message: error.message || 'Failed to parse LLM output',\n original_output: rawOutput\n }\n });\n continue;\n }\n } else if (typeof rawOutput === 'object' && rawOutput !== null) {\n // In case the LLM node already returns an object\n parsed = rawOutput;\n } else {\n newItems.push({\n json: {\n parse_error: true,\n error_message: 'Unexpected output type from LLM',\n original_output: rawOutput\n }\n });\n continue;\n }\n\n const ratingDist = parsed.rating_distribution || {};\n const sentimentDist = parsed.sentiment_distribution || {};\n const topicDist = parsed.topic_distribution || {};\n\n // Build a flat JSON object for Google Sheets\n const flat = {\n // Basic metadata\n source_url: parsed.source_url || \"\",\n source_domain: parsed.source_domain || \"\",\n estimated_total_reviews: parsed.estimated_total_reviews ?? null,\n average_rating: parsed.average_rating ?? null,\n rating_scale_max: parsed.rating_scale_max ?? 5,\n\n // Rating distribution (1\u20135)\n rating_1: ratingDist[\"1\"] ?? 0,\n rating_2: ratingDist[\"2\"] ?? 0,\n rating_3: ratingDist[\"3\"] ?? 0,\n rating_4: ratingDist[\"4\"] ?? 0,\n rating_5: ratingDist[\"5\"] ?? 0,\n\n // Sentiment distribution\n sentiment_positive: sentimentDist.positive ?? 0,\n sentiment_neutral: sentimentDist.neutral ?? 0,\n sentiment_negative: sentimentDist.negative ?? 0,\n\n // Topic distribution\n topic_pricing: topicDist.pricing ?? 0,\n topic_usability: topicDist.usability ?? 0,\n topic_features: topicDist.features ?? 0,\n topic_support: topicDist.support ?? 0,\n topic_performance: topicDist.performance ?? 0,\n topic_other: topicDist.other ?? 0,\n\n // Arrays \u2192 strings\n top_positive_keywords: Array.isArray(parsed.top_positive_keywords)\n ? parsed.top_positive_keywords.join(\", \")\n : \"\",\n\n top_negative_keywords: Array.isArray(parsed.top_negative_keywords)\n ? parsed.top_negative_keywords.join(\", \")\n : \"\",\n\n top_praises: Array.isArray(parsed.top_praises)\n ? parsed.top_praises.join(\"\\n\")\n : \"\",\n\n top_complaints: Array.isArray(parsed.top_complaints)\n ? parsed.top_complaints.join(\"\\n\")\n : \"\",\n\n // Text fields\n recent_trend_summary: parsed.recent_trend_summary || \"\",\n data_quality_notes: parsed.data_quality_notes || \"\"\n };\n\n newItems.push({ json: flat });\n}\n\nreturn newItems;\n"
},
"typeVersion": 2
},
{
"id": "7ce9b06a-402b-4ff6-b857-431f01c75f2a",
"name": "Get row(s) in sheet",
"type": "n8n-nodes-base.googleSheets",
"position": [
688,
560
],
"parameters": {
"options": {},
"sheetName": {
"__rl": true,
"mode": "list",
"value": "gid=0",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1TqXzrR4lq9oijo09pLFLqSUz2OK2uCRKu7CPQz0MxWo/edit#gid=0",
"cachedResultName": "input"
},
"documentId": {
"__rl": true,
"mode": "list",
"value": "1TqXzrR4lq9oijo09pLFLqSUz2OK2uCRKu7CPQz0MxWo",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1TqXzrR4lq9oijo09pLFLqSUz2OK2uCRKu7CPQz0MxWo/edit?usp=drivesdk",
"cachedResultName": "url_feedback_truspilot"
}
},
"credentials": {
"googleSheetsOAuth2Api": {
"name": "<your credential>"
}
},
"typeVersion": 4.7
},
{
"id": "f26790bb-a333-4e1d-9309-f2e30a6c59fd",
"name": "Append row in sheet",
"type": "n8n-nodes-base.googleSheets",
"position": [
2304,
352
],
"parameters": {
"columns": {
"value": {
"source_url": "={{ $json.source_url }}",
"average_rating": "={{ $json.average_rating }}",
"sentiment_neutral": "={{ $json.sentiment_neutral }}",
"sentiment_negative": "={{ $json.sentiment_negative }}",
"sentiment_positive": "={{ $json.sentiment_positive }}",
"recent_trend_summary": "={{ $json.recent_trend_summary }}",
"top_negative_keywords": "={{ $json.top_negative_keywords }}",
"top_positive_keywords": "={{ $json.top_positive_keywords }}",
"estimated_total_reviews": "={{ $json.estimated_total_reviews }}"
},
"schema": [
{
"id": "source_url",
"type": "string",
"display": true,
"required": false,
"displayName": "source_url",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "estimated_total_reviews",
"type": "string",
"display": true,
"required": false,
"displayName": "estimated_total_reviews",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "average_rating",
"type": "string",
"display": true,
"required": false,
"displayName": "average_rating",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "sentiment_positive",
"type": "string",
"display": true,
"required": false,
"displayName": "sentiment_positive",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "sentiment_neutral",
"type": "string",
"display": true,
"required": false,
"displayName": "sentiment_neutral",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "sentiment_negative",
"type": "string",
"display": true,
"required": false,
"displayName": "sentiment_negative",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "top_positive_keywords",
"type": "string",
"display": true,
"required": false,
"displayName": "top_positive_keywords",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "top_negative_keywords",
"type": "string",
"display": true,
"required": false,
"displayName": "top_negative_keywords",
"defaultMatch": false,
"canBeUsedToMatch": true
},
{
"id": "recent_trend_summary",
"type": "string",
"display": true,
"required": false,
"displayName": "recent_trend_summary",
"defaultMatch": false,
"canBeUsedToMatch": true
}
],
"mappingMode": "defineBelow",
"matchingColumns": [],
"attemptToConvertTypes": false,
"convertFieldsToString": false
},
"options": {},
"operation": "append",
"sheetName": {
"__rl": true,
"mode": "list",
"value": 697979134,
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1TqXzrR4lq9oijo09pLFLqSUz2OK2uCRKu7CPQz0MxWo/edit#gid=697979134",
"cachedResultName": "output"
},
"documentId": {
"__rl": true,
"mode": "list",
"value": "1TqXzrR4lq9oijo09pLFLqSUz2OK2uCRKu7CPQz0MxWo",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1TqXzrR4lq9oijo09pLFLqSUz2OK2uCRKu7CPQz0MxWo/edit?usp=drivesdk",
"cachedResultName": "url_feedback_truspilot"
}
},
"credentials": {
"googleSheetsOAuth2Api": {
"name": "<your credential>"
}
},
"typeVersion": 4.7
},
{
"id": "6b7f37a7-354f-4f5d-a62b-d70aeb497387",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-128,
-144
],
"parameters": {
"height": 1200,
"content": "## What this workflow does\nThis workflow scrapes **customer reviews from Trustpilot**, analyzes them with AI, and keeps both **Salesforce** and **Google Sheets** automatically updated with customer sentiment insights.\n\nIt uses **Decodo** to reliably extract review content from Trustpilot, processes the text with **OpenAI**, and orchestrates everything using **n8n**.\n\nDecodo (scraping layer): \n\ud83d\udc49 https://visit.decodo.com/raqXGD\n\n\n## How it works (high level)\n\n1. Reads **Trustpilot review URLs** and **Salesforce Account IDs** from Google Sheets \n2. Scrapes Trustpilot reviews using **Decodo** \n3. Uses AI to summarize sentiment, trends, and key positives/negatives \n4. Generates **two outputs in parallel** \n\n## Outputs generated\n\n### 1. Salesforce Account update \nThe workflow updates an **existing Salesforce Account** by writing the AI-generated sentiment summary into a **custom text field** (e.g. `recent_trend_summary__c`).\n\nThis brings external customer feedback directly into Salesforce, so teams can:\n- See real customer sentiment inside the CRM \n- Make faster, better-informed decisions \n- Avoid manual review checks \n\n### 2. Google Sheets analytics dataset \nAt the same time, the workflow appends structured review metrics into Google Sheets, including:\n- Estimated total reviews \n- Average rating \n- Positive / neutral / negative sentiment counts \n- Top positive and negative keywords \n- Trend summary \n\nThis sheet becomes a **central analytics layer** for dashboards, reporting, and historical comparison.\n\n\n## How to configure it (general)\n\n- **Google Sheets**: provide review URLs + Salesforce Account IDs \n- **Decodo**: add your API key to scrape Trustpilot reliably \n \ud83d\udc49 https://visit.decodo.com/raqXGD \n- **OpenAI**: add your API key for sentiment summarization \n- **Salesforce**:\n - Create a custom **Text (255)** field on Account\n - Connect Salesforce credentials in n8n\n - The workflow updates existing Accounts only (no creation)"
},
"typeVersion": 1
},
{
"id": "cac8d1e3-de91-47d4-96e8-7a4109a32d7b",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
1072,
176
],
"parameters": {
"color": 7,
"width": 384,
"height": 128,
"content": "## Data Extraction \nReads Trustpilot URLs and Salesforce Account IDs from Google Sheets and controls the execution flow"
},
"typeVersion": 1
},
{
"id": "19a14699-c1dd-4368-91cd-a91c7a5278a1",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
1584,
176
],
"parameters": {
"color": 7,
"width": 512,
"height": 128,
"content": "## AI Analysis \nScrapes Trustpilot reviews via **Decodo**, cleans the text, and generates sentiment insights using OpenAI"
},
"typeVersion": 1
},
{
"id": "55190458-90d6-44b5-ae91-d9c0b05dd82d",
"name": "Sticky Note5",
"type": "n8n-nodes-base.stickyNote",
"position": [
3232,
48
],
"parameters": {
"color": 7,
"width": 848,
"height": 624,
"content": "## Data Output \n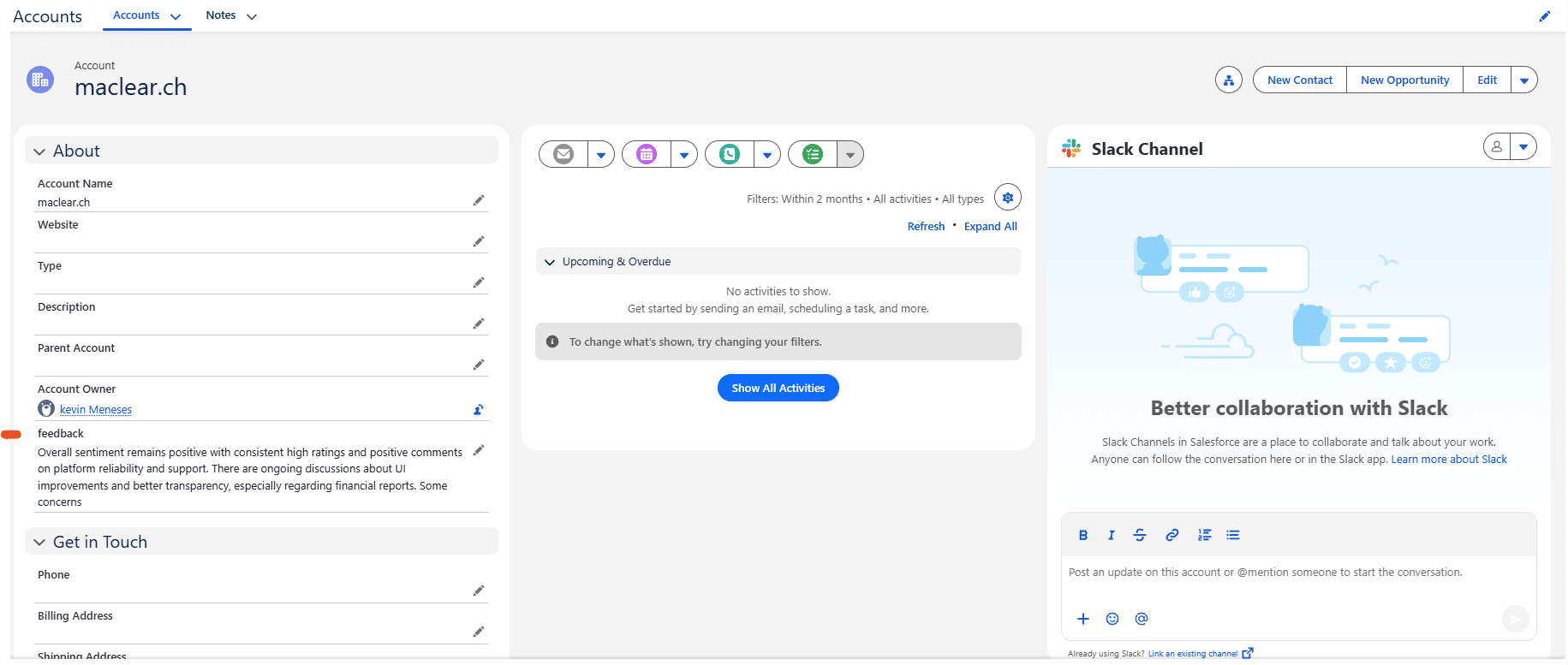\n"
},
"typeVersion": 1
},
{
"id": "de95cc00-c6a2-4226-ab10-aa7d1b3d0efa",
"name": "Decodo",
"type": "@decodo/n8n-nodes-decodo.decodo",
"position": [
1280,
352
],
"parameters": {
"url": "={{ $('Get row(s) in sheet').item.json.url }}"
},
"credentials": {
"decodoApi": {
"name": "<your credential>"
}
},
"typeVersion": 1
},
{
"id": "bf870fff-71bd-4b9c-ac28-6b2b1fc64da3",
"name": "Create or update an account",
"type": "n8n-nodes-base.salesforce",
"position": [
2976,
476
],
"parameters": {
"name": "={{ $('Code in JavaScript').item.json.entity_slug }}",
"resource": "account",
"operation": "upsert",
"externalId": "Id",
"externalIdValue": "={{ $('Get row(s) in sheet').item.json.salesforce_account_id }}",
"additionalFields": {
"customFieldsUi": {
"customFieldsValues": [
{
"value": "={{ $json.recent_trend_summary }}",
"fieldId": "feedback__c"
}
]
}
}
},
"credentials": {
"salesforceOAuth2Api": {
"name": "<your credential>"
}
},
"typeVersion": 1
},
{
"id": "b63a97fe-e81f-42b3-bf4c-9a48766ea103",
"name": "OpenAI Chat Model",
"type": "@n8n/n8n-nodes-langchain.lmChatOpenAi",
"position": [
1800,
576
],
"parameters": {
"model": {
"__rl": true,
"mode": "list",
"value": "gpt-4.1-nano",
"cachedResultName": "gpt-4.1-nano"
},
"options": {},
"builtInTools": {}
},
"credentials": {
"openAiApi": {
"name": "<your credential>"
}
},
"typeVersion": 1.3
},
{
"id": "6b55d083-2370-478a-812b-02cc06c7fa3a",
"name": "Code in JavaScript2",
"type": "n8n-nodes-base.code",
"position": [
2752,
352
],
"parameters": {
"jsCode": "function truncateTo255Smart(value) {\n if (!value) return \"\";\n\n const text = String(value);\n\n // If already within limit, return as is\n if (text.length <= 255) {\n return text;\n }\n\n // Cut to max length\n const truncated = text.slice(0, 255);\n\n // Try to avoid cutting words\n const lastSpace = truncated.lastIndexOf(\" \");\n\n return lastSpace > 200\n ? truncated.slice(0, lastSpace)\n : truncated;\n}\n\n// Apply truncation to the Salesforce field\nconst safeTrendSummary = truncateTo255Smart($input.first().json.recent_trend_summary);\n\nreturn [\n {\n json: {\n\n recent_trend_summary: safeTrendSummary\n }\n }\n];\n"
},
"typeVersion": 2
},
{
"id": "669cde21-0d71-45d8-aae8-1104803a67b6",
"name": "If",
"type": "n8n-nodes-base.if",
"position": [
2528,
352
],
"parameters": {
"options": {},
"conditions": {
"options": {
"version": 3,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "9790b05b-3c77-40d4-b33c-04f97c22129d",
"operator": {
"type": "string",
"operation": "notEquals"
},
"leftValue": "={{ $('Get row(s) in sheet').item.json.salesforce_account_id }}",
"rightValue": ""
}
]
}
},
"typeVersion": 2.3
},
{
"id": "28e7741a-ef0b-470c-8d71-97fe9013a6d9",
"name": "Loop Over Items",
"type": "n8n-nodes-base.splitInBatches",
"position": [
1056,
368
],
"parameters": {
"options": {}
},
"typeVersion": 3
},
{
"id": "45ac4709-d499-40f4-944a-b441f0e911ed",
"name": "Sticky Note3",
"type": "n8n-nodes-base.stickyNote",
"position": [
2288,
192
],
"parameters": {
"color": 7,
"width": 448,
"height": 128,
"content": "## CRM + Google sheets update\nUpdates the Salesforce Account with the sentiment summary and stores full analytics in Google Sheets"
},
"typeVersion": 1
},
{
"id": "5311f4f3-49aa-463e-af61-20b09df7aaab",
"name": "Sticky Note4",
"type": "n8n-nodes-base.stickyNote",
"position": [
432,
144
],
"parameters": {
"color": 7,
"width": 480,
"height": 288,
"content": "## Input \n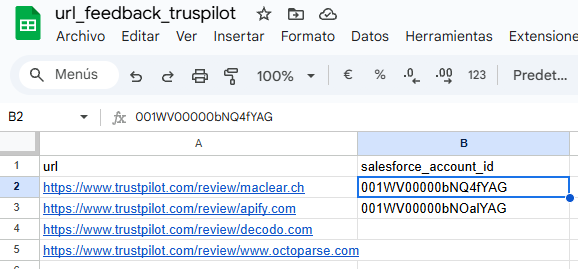"
},
"typeVersion": 1
}
],
"active": false,
"settings": {
"executionOrder": "v1"
},
"versionId": "266ddd23-8bd8-49d1-9903-44e201471260",
"connections": {
"If": {
"main": [
[
{
"node": "Code in JavaScript2",
"type": "main",
"index": 0
}
],
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"Decodo": {
"main": [
[
{
"node": "Code in JavaScript",
"type": "main",
"index": 0
}
]
]
},
"AI Agent": {
"main": [
[
{
"node": "Code in JavaScript1",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Items": {
"main": [
[],
[
{
"node": "Decodo",
"type": "main",
"index": 0
}
]
]
},
"OpenAI Chat Model": {
"ai_languageModel": [
[
{
"node": "AI Agent",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Code in JavaScript": {
"main": [
[
{
"node": "AI Agent",
"type": "main",
"index": 0
}
]
]
},
"Append row in sheet": {
"main": [
[
{
"node": "If",
"type": "main",
"index": 0
}
]
]
},
"Code in JavaScript1": {
"main": [
[
{
"node": "Append row in sheet",
"type": "main",
"index": 0
}
]
]
},
"Code in JavaScript2": {
"main": [
[
{
"node": "Create or update an account",
"type": "main",
"index": 0
}
]
]
},
"Get row(s) in sheet": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"Create or update an account": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"When clicking \u2018Execute workflow\u2019": {
"main": [
[
{
"node": "Get row(s) in sheet",
"type": "main",
"index": 0
}
]
]
}
}
}
Credentials you'll need
Each integration node will prompt for credentials when you import. We strip credential IDs before publishing — you'll add your own.
decodoApigoogleSheetsOAuth2ApiopenAiApisalesforceOAuth2Api
For the full experience including quality scoring and batch install features for each workflow upgrade to Pro
About this workflow
This workflow scrapes customer reviews from Trustpilot, analyzes them with AI, and keeps both Salesforce and Google Sheets automatically updated with customer sentiment insights.
Source: https://n8n.io/workflows/11489/ — original creator credit. Request a take-down →
Related workflows
Workflows that share integrations, category, or trigger type with this one. All free to copy and import.
This workflow contains community nodes that are only compatible with the self-hosted version of n8n.
This workflow contains community nodes that are only compatible with the self-hosted version of n8n.
Submit your webinar recording URL along with the webinar title, host name, company name, date, and CTA link and the workflow automatically handles every follow-up. WayinVideo summarizes the webinar an
This workflow contains community nodes that are only compatible with the self-hosted version of n8n.
This workflow automatically audits web pages for SEO issues and generates an executive-friendly SEO report using AI.