This workflow corresponds to n8n.io template #10565 — we link there as the canonical source.
This workflow follows the Documentdefaultdataloader → Google Gemini Embeddings recipe pattern — see all workflows that pair these two integrations.
The workflow JSON
Copy or download the full n8n JSON below. Paste it into a new n8n workflow, add your credentials, activate. Full import guide →
{
"id": "Xs7mwlQCtwVn5iCZ",
"meta": {
"templateId": "6212",
"templateCredsSetupCompleted": true
},
"name": "Website Content Scraper to Knowledge Base Vector Store (Rag-Ready)",
"tags": [
{
"id": "6ge76XAEF4IWBzQI",
"name": "Content Extraction",
"createdAt": "2025-11-06T11:25:09.571Z",
"updatedAt": "2025-11-06T11:25:09.571Z"
},
{
"id": "G2fbfHeKIPv2Lpo9",
"name": "RAG",
"createdAt": "2025-11-05T11:27:13.020Z",
"updatedAt": "2025-11-05T11:27:13.020Z"
},
{
"id": "Tx5TGVSKbShwuivF",
"name": "Web Scraping",
"createdAt": "2025-11-06T11:24:12.990Z",
"updatedAt": "2025-11-06T11:24:12.990Z"
},
{
"id": "bKbGwizrLkaEwYLa",
"name": "Vector Database",
"createdAt": "2025-11-06T11:24:27.424Z",
"updatedAt": "2025-11-06T11:24:27.424Z"
},
{
"id": "fnfpUfqgvsA7IjPn",
"name": "Apify",
"createdAt": "2025-11-06T11:24:19.510Z",
"updatedAt": "2025-11-06T11:24:19.510Z"
},
{
"id": "tqLQaLdCHROp2cPu",
"name": "Knowledge Base",
"createdAt": "2025-11-06T11:24:39.047Z",
"updatedAt": "2025-11-06T11:24:39.047Z"
}
],
"nodes": [
{
"id": "b7541584-131f-4868-b8dd-053ab509ab1b",
"name": "Supabase Vector Store",
"type": "@n8n/n8n-nodes-langchain.vectorStoreSupabase",
"position": [
976,
368
],
"parameters": {
"mode": "insert",
"options": {},
"tableName": {
"__rl": true,
"mode": "list",
"value": "documents",
"cachedResultName": "documents"
},
"embeddingBatchSize": 800
},
"credentials": {
"supabaseApi": {
"name": "<your credential>"
}
},
"typeVersion": 1.1
},
{
"id": "ddb37d99-4e8d-4eef-83da-6b3088360062",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1168,
192
],
"parameters": {
"color": 5,
"width": 1072,
"height": 820,
"content": "## Input & Routing\nForm collects URL and scraping preferences. Switch node routes to 3 scraper configs based on user choice."
},
"typeVersion": 1
},
{
"id": "d6b1e754-2957-4334-b2e5-44a3a2a5286e",
"name": "Embeddings Google Gemini",
"type": "@n8n/n8n-nodes-langchain.embeddingsGoogleGemini",
"position": [
912,
592
],
"parameters": {},
"credentials": {
"googlePalmApi": {
"name": "<your credential>"
}
},
"typeVersion": 1
},
{
"id": "c7d6b146-3fee-4e63-86ad-be8cdfb958ca",
"name": "Improve Content Structure Quality",
"type": "n8n-nodes-base.code",
"position": [
544,
560
],
"parameters": {
"jsCode": "// Flattened output for Default Data Loader\nreturn items.map(({ json }) => {\n const text = (json.markdown || json.text || '').trim();\n const firstLine = (text.split('\\n').find(Boolean) || '').replace(/^#+\\s*/, '').slice(0,120);\n\n return {\n json: {\n text, // your main text\n title: firstLine || '', // each metadata item now top-level\n url: json.url || '',\n type: 'webpage',\n section: json.section || 'General',\n created_at: new Date().toISOString()\n }\n };\n});\n"
},
"typeVersion": 2
},
{
"id": "fcc66f40-2945-4e46-a7d3-5e9c81134d91",
"name": "Recursive Character Text Splitter",
"type": "@n8n/n8n-nodes-langchain.textSplitterRecursiveCharacterTextSplitter",
"position": [
1072,
752
],
"parameters": {
"options": {
"splitCode": "markdown"
},
"chunkSize": 800,
"chunkOverlap": 80
},
"typeVersion": 1
},
{
"id": "dfe8c7b7-1f39-45d8-8f9b-10b0c344a750",
"name": "Default Data Loader",
"type": "@n8n/n8n-nodes-langchain.documentDefaultDataLoader",
"position": [
1072,
592
],
"parameters": {
"options": {
"metadata": {
"metadataValues": [
{
"name": "title",
"value": "={{ $('Improve Content Structure Quality').item.json.title }}"
},
{
"name": "url",
"value": "={{ $('Improve Content Structure Quality').item.json.url }}"
},
{
"name": "type",
"value": "={{ $('Improve Content Structure Quality').item.json.type }}"
},
{
"name": "section",
"value": "={{ $('Improve Content Structure Quality').item.json.section }}"
},
{
"name": "created_at",
"value": "={{ $('Improve Content Structure Quality').item.json.created_at }}"
}
]
}
},
"jsonData": "={{ $('Improve Content Structure Quality').item.json.text }}",
"jsonMode": "expressionData",
"textSplittingMode": "custom"
},
"typeVersion": 1.1
},
{
"id": "0cb16f73-e8b1-4dfa-812e-fc3b5b75a5dd",
"name": "Clean Data",
"type": "n8n-nodes-base.set",
"position": [
336,
560
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "6866b435-f703-458f-9ca2-68e38919c67d",
"name": "url",
"type": "string",
"value": "={{ $json.url }}"
},
{
"id": "5400376c-c380-4c49-9523-b52d3a4d8c78",
"name": "markdown",
"type": "string",
"value": "={{ $json.markdown }}"
}
]
}
},
"executeOnce": false,
"typeVersion": 3.4
},
{
"id": "372da59d-2fd7-4dbf-942c-735c3b8a81ad",
"name": "Enter Website URL and Settings",
"type": "n8n-nodes-base.formTrigger",
"position": [
-1072,
336
],
"parameters": {
"options": {
"appendAttribution": false
},
"formTitle": "Enter Website URL and Settings",
"formFields": {
"values": [
{
"fieldLabel": "Website page (URL) to scrape",
"placeholder": "e.g. https://tidycurve.com",
"requiredField": true
},
{
"fieldType": "radio",
"fieldLabel": "Scrape all pages available on the domain, or only the page provided?",
"fieldOptions": {
"values": [
{
"option": "Scrape all pages on the domain"
},
{
"option": "Scrape only the one URL provided"
}
]
},
"requiredField": true
},
{
"fieldType": "number",
"fieldLabel": "Max number of scraped pages to return",
"placeholder": "E.g. 10, 20, etc. Leave empty to scrape all available"
}
]
},
"formDescription": "Provide the full website URL you want to scrape.\nIf you want to scrape an entire website, simply leave the \"Max number of pages to scrape\" field, empty.\nOtherwise, you can enter a number there to limit the scraped pages."
},
"typeVersion": 2.3
},
{
"id": "1e839b66-f236-4ebc-8585-3ecbace31d80",
"name": "Prepare Settings for Apify Web Scraper",
"type": "n8n-nodes-base.switch",
"position": [
-640,
336
],
"parameters": {
"rules": {
"values": [
{
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "91e27c20-50a5-4f00-b329-be55a9f24568",
"operator": {
"type": "string",
"operation": "equals"
},
"leftValue": "={{ $json.scrapeAll }}",
"rightValue": "Scrape all pages on the domain"
}
]
}
},
{
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "bfa6cfae-3b5c-4d86-b2dc-7e2e276e9828",
"operator": {
"name": "filter.operator.equals",
"type": "string",
"operation": "equals"
},
"leftValue": "={{ $json.scrapeAll }}",
"rightValue": "Scrape only the one URL provided"
}
]
}
}
]
},
"options": {}
},
"typeVersion": 3.3
},
{
"id": "b37e7166-ff9f-4ea2-9c8c-ac1aa8356d01",
"name": "Set Data in Correct Request Format",
"type": "n8n-nodes-base.set",
"position": [
-848,
336
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "fab1ebb4-cb8e-4fb2-80ad-f563e37ce80a",
"name": "url",
"type": "string",
"value": "={{ $json[\"Website page (URL) to scrape\"] }}"
},
{
"id": "e36d0f03-d69e-4fc1-8518-c6a451712380",
"name": "scrapeAll",
"type": "string",
"value": "={{ $json[\"Scrape all pages available on the domain, or only the page provided?\"] }}"
},
{
"id": "3db2d28b-f136-46fa-885d-8c4f62aa7d06",
"name": "maxCrawlPages",
"type": "number",
"value": "={{ $json[\"Max number of scraped pages to return\"] }}"
},
{
"id": "e124abab-c87c-4a06-810a-5e37285ee188",
"name": "maxResults",
"type": "number",
"value": "={{ $json[\"Max number of scraped pages to return\"] }}"
}
]
}
},
"typeVersion": 3.4
},
{
"id": "435956de-3fc8-4f45-b458-dc83e6fa076a",
"name": "Run Apify Scraper: Scrape All - w/Limit",
"type": "n8n-nodes-base.httpRequest",
"position": [
32,
560
],
"parameters": {
"url": "https://api.apify.com/v2/acts/apify~website-content-crawler/run-sync-get-dataset-items",
"method": "POST",
"options": {
"batching": {
"batch": {
"batchSize": 1
}
}
},
"jsonBody": "={\n \"aggressivePrune\": false,\n \"blockMedia\": false,\n \"clickElementsCssSelector\": \"[aria-expanded=\\\"false\\\"]\",\n \"clientSideMinChangePercentage\": 15,\n \"crawlerType\": \"playwright:firefox\",\n \"debugLog\": false,\n \"debugMode\": false,\n \"expandIframes\": true,\n \"ignoreCanonicalUrl\": true,\n \"ignoreHttpsErrors\": false,\n \"keepUrlFragments\": false,\n \"maxCrawlPages\": {{ $json.maxCrawlPages }},\n \"maxResults\": {{ $json.maxResults }},\n \"proxyConfiguration\": {\n \"useApifyProxy\": true\n },\n \"readableTextCharThreshold\": 100,\n \"removeCookieWarnings\": true,\n \"removeElementsCssSelector\": \"nav, footer, script, style, noscript, svg, img[src^='data:'],\\n[role=\\\"alert\\\"],\\n[role=\\\"banner\\\"],\\n[role=\\\"dialog\\\"],\\n[role=\\\"alertdialog\\\"],\\n[role=\\\"region\\\"][aria-label*=\\\"skip\\\" i],\\n[aria-modal=\\\"true\\\"]\",\n \"renderingTypeDetectionPercentage\": 10,\n \"respectRobotsTxtFile\": false,\n \"saveFiles\": false,\n \"saveHtml\": false,\n \"saveHtmlAsFile\": false,\n \"saveMarkdown\": true,\n \"saveScreenshots\": false,\n \"startUrls\": [\n {\n \"url\": \"{{ $('Set Data in Correct Request Format').item.json.url }}\",\n \"method\": \"GET\"\n }\n ],\n \"storeSkippedUrls\": false,\n \"useSitemaps\": true\n}",
"sendBody": true,
"sendQuery": true,
"specifyBody": "json",
"queryParameters": {
"parameters": [
{
"name": "token",
"value": "YOUR_APIFY_API_KEY"
}
]
}
},
"typeVersion": 4.2
},
{
"id": "30458767-c553-4f17-a91c-d608aab3115b",
"name": "Run Apify Scraper: Scrape 1 URL Only",
"type": "n8n-nodes-base.httpRequest",
"position": [
32,
768
],
"parameters": {
"url": "https://api.apify.com/v2/acts/apify~website-content-crawler/run-sync-get-dataset-items",
"method": "POST",
"options": {
"batching": {
"batch": {
"batchSize": 1
}
}
},
"jsonBody": "={\n \"aggressivePrune\": false,\n \"blockMedia\": false,\n \"clickElementsCssSelector\": \"[aria-expanded=\\\"false\\\"]\",\n \"clientSideMinChangePercentage\": 15,\n \"crawlerType\": \"playwright:firefox\",\n \"debugLog\": false,\n \"debugMode\": false,\n \"expandIframes\": true,\n \"ignoreCanonicalUrl\": true,\n \"ignoreHttpsErrors\": false,\n \"keepUrlFragments\": false,\n \"maxCrawlPages\": 1,\n \"maxResults\": 1,\n \"proxyConfiguration\": {\n \"useApifyProxy\": true\n },\n \"readableTextCharThreshold\": 100,\n \"removeCookieWarnings\": true,\n \"removeElementsCssSelector\": \"nav, footer, script, style, noscript, svg, img[src^='data:'],\\n[role=\\\"alert\\\"],\\n[role=\\\"banner\\\"],\\n[role=\\\"dialog\\\"],\\n[role=\\\"alertdialog\\\"],\\n[role=\\\"region\\\"][aria-label*=\\\"skip\\\" i],\\n[aria-modal=\\\"true\\\"]\",\n \"renderingTypeDetectionPercentage\": 10,\n \"respectRobotsTxtFile\": false,\n \"saveFiles\": false,\n \"saveHtml\": false,\n \"saveHtmlAsFile\": false,\n \"saveMarkdown\": true,\n \"saveScreenshots\": false,\n \"startUrls\": [\n {\n \"url\": \"{{ $('Set Data in Correct Request Format').item.json.url }}\",\n \"method\": \"GET\"\n }\n ],\n \"storeSkippedUrls\": false,\n \"useSitemaps\": true\n}",
"sendBody": true,
"sendQuery": true,
"specifyBody": "json",
"queryParameters": {
"parameters": [
{
"name": "token",
"value": "YOUR_APIFY_API_KEY"
}
]
}
},
"typeVersion": 4.2
},
{
"id": "8bdceb21-a543-41ed-b952-53690f157ed0",
"name": "No Limit to Number of Scraped Pages?",
"type": "n8n-nodes-base.if",
"position": [
-304,
352
],
"parameters": {
"options": {},
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "loose"
},
"combinator": "and",
"conditions": [
{
"id": "ca2b8e48-84f1-4c20-9f61-70964112e173",
"operator": {
"type": "number",
"operation": "lt"
},
"leftValue": "={{ $json.maxCrawlPages }}",
"rightValue": "=1"
}
]
},
"looseTypeValidation": true
},
"typeVersion": 2.2
},
{
"id": "2bab90a9-7440-4c30-976e-7c1ed7d565e3",
"name": "Run Apify Scraper: Scrape All - No Limit",
"type": "n8n-nodes-base.httpRequest",
"position": [
32,
336
],
"parameters": {
"url": "https://api.apify.com/v2/acts/apify~website-content-crawler/run-sync-get-dataset-items",
"method": "POST",
"options": {
"batching": {
"batch": {
"batchSize": 1
}
}
},
"jsonBody": "={\n \"aggressivePrune\": false,\n \"blockMedia\": false,\n \"clickElementsCssSelector\": \"[aria-expanded=\\\"false\\\"]\",\n \"clientSideMinChangePercentage\": 15,\n \"crawlerType\": \"playwright:firefox\",\n \"debugLog\": false,\n \"debugMode\": false,\n \"expandIframes\": true,\n \"ignoreCanonicalUrl\": true,\n \"ignoreHttpsErrors\": false,\n \"keepUrlFragments\": false,\n \"proxyConfiguration\": {\n \"useApifyProxy\": true\n },\n \"readableTextCharThreshold\": 100,\n \"removeCookieWarnings\": true,\n \"removeElementsCssSelector\": \"nav, footer, script, style, noscript, svg, img[src^='data:'],\\n[role=\\\"alert\\\"],\\n[role=\\\"banner\\\"],\\n[role=\\\"dialog\\\"],\\n[role=\\\"alertdialog\\\"],\\n[role=\\\"region\\\"][aria-label*=\\\"skip\\\" i],\\n[aria-modal=\\\"true\\\"]\",\n \"renderingTypeDetectionPercentage\": 10,\n \"respectRobotsTxtFile\": false,\n \"saveFiles\": false,\n \"saveHtml\": false,\n \"saveHtmlAsFile\": false,\n \"saveMarkdown\": true,\n \"saveScreenshots\": false,\n \"startUrls\": [\n {\n \"url\": \"{{ $('Set Data in Correct Request Format').item.json.url }}\",\n \"method\": \"GET\"\n }\n ],\n \"storeSkippedUrls\": false,\n \"useSitemaps\": true\n}",
"sendBody": true,
"sendQuery": true,
"specifyBody": "json",
"queryParameters": {
"parameters": [
{
"name": "token",
"value": "YOUR_APIFY_API_KEY"
}
]
}
},
"typeVersion": 4.2
},
{
"id": "87f464c8-6daa-45fb-93a7-4acaa64d9685",
"name": "Sticky Note4",
"type": "n8n-nodes-base.stickyNote",
"position": [
-64,
192
],
"parameters": {
"color": 3,
"width": 816,
"height": 816,
"content": "## Web Scraping\nThree Apify paths: all pages unlimited, all pages with limit, or single URL. Smart filtering removes unwanted elements."
},
"typeVersion": 1
},
{
"id": "0676473a-1c75-4bdb-b88e-df0156aa5667",
"name": "Sticky Note5",
"type": "n8n-nodes-base.stickyNote",
"position": [
784,
192
],
"parameters": {
"color": 4,
"width": 640,
"height": 784,
"content": "## Processing & Storage\nClean data \u2192 Add metadata \u2192 Chunk text \u2192 Generate embeddings \u2192 Store in Supabase. Batch size: 800."
},
"typeVersion": 1
},
{
"id": "b4bfe44a-1129-4ca5-9c1e-b898741bc1e9",
"name": "Sticky Note7",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1168,
-672
],
"parameters": {
"width": 864,
"height": 832,
"content": "# **Website Content to RAG-Ready Knowledge Base For AI Chatbots**\n\n Convert any website into a searchable vector database for AI chatbots. Submit a URL, choose scraping scope, and this workflow handles everything: scraping, cleaning, chunking, embedding, and storing in Supabase.\n\n ## What it does\n - Scrapes websites using Apify (3 modes: full site unlimited, full site limited, single URL)\n - Cleans content (removes navigation, footer, ads, cookie banners, etc)\n - Chunks text (800 chars, markdown-aware)\n - Generates embeddings (Google Gemini, 768 dimensions)\n - Stores in Supabase vector database\n\n ## Requirements\n - Apify account + API token\n - Supabase database with pgvector extension\n - Google Gemini API key\n\n ## Setup\n 1. Create Supabase `documents` table with embedding column (vector 768). *[Run this SQL query](https://docs.langchain.com/oss/javascript/integrations/vectorstores/supabase) in your Supabase project to enable the vector store setup* \n 2. Add your Apify API token to all three \"Run Apify Scraper\" nodes\n 3. Add Supabase and Gemini credentials\n 4. Test with small site (5-10 pages) or single page/URL first\n\n ## Next steps\n Connect your vector store to an AI chatbot for RAG-powered Q&A, or build semantic search features into your apps.\n\n **Tip:** Start with page limits to test content quality before full-site scraping. Review chunks in Supabase and adjust Apify filters if needed for better vector embeddings."
},
"typeVersion": 1
},
{
"id": "37acfe02-2722-4515-a6c3-e8c70d66a29b",
"name": "Sticky Note6",
"type": "n8n-nodes-base.stickyNote",
"position": [
-272,
-608
],
"parameters": {
"color": 7,
"width": 1344,
"height": 768,
"content": "## Sample Outputs\n\n### Apify actor \"runs\" in Apify Dashboard from this workflow\n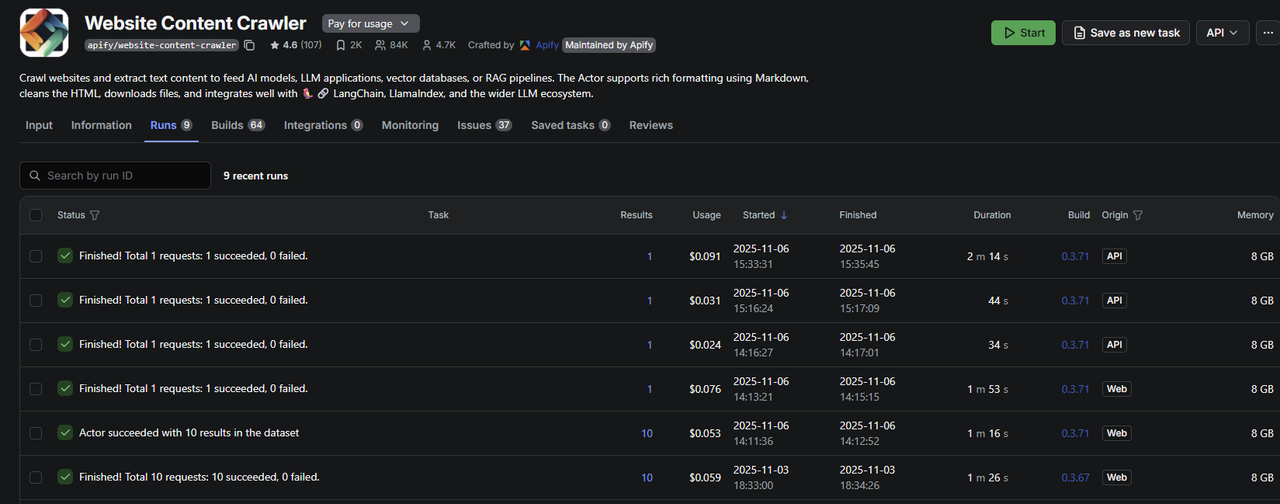\n"
},
"typeVersion": 1
},
{
"id": "b1c6f18b-8a82-4dd2-bf04-f9f11f562d94",
"name": "Sticky Note8",
"type": "n8n-nodes-base.stickyNote",
"position": [
1056,
-544
],
"parameters": {
"color": 7,
"width": 1360,
"height": 704,
"content": "### Supabase `docuemnts` table with scraped website content ingested in chunks with vector embeddings\n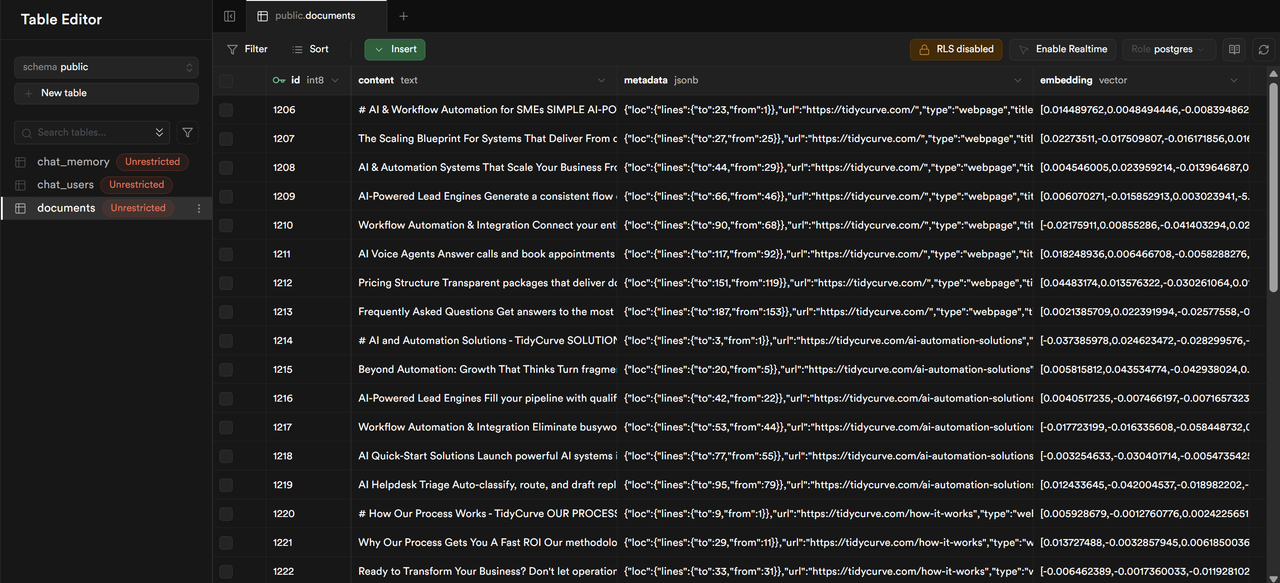\n"
},
"typeVersion": 1
}
],
"active": false,
"settings": {},
"versionId": "b4924314-771f-46f9-b60e-2b15a4e90ae1",
"connections": {
"Clean Data": {
"main": [
[
{
"node": "Improve Content Structure Quality",
"type": "main",
"index": 0
}
]
]
},
"Default Data Loader": {
"ai_document": [
[
{
"node": "Supabase Vector Store",
"type": "ai_document",
"index": 0
}
]
]
},
"Embeddings Google Gemini": {
"ai_embedding": [
[
{
"node": "Supabase Vector Store",
"type": "ai_embedding",
"index": 0
}
]
]
},
"Enter Website URL and Settings": {
"main": [
[
{
"node": "Set Data in Correct Request Format",
"type": "main",
"index": 0
}
]
]
},
"Improve Content Structure Quality": {
"main": [
[
{
"node": "Supabase Vector Store",
"type": "main",
"index": 0
}
]
]
},
"Recursive Character Text Splitter": {
"ai_textSplitter": [
[
{
"node": "Default Data Loader",
"type": "ai_textSplitter",
"index": 0
}
]
]
},
"Set Data in Correct Request Format": {
"main": [
[
{
"node": "Prepare Settings for Apify Web Scraper",
"type": "main",
"index": 0
}
]
]
},
"No Limit to Number of Scraped Pages?": {
"main": [
[
{
"node": "Run Apify Scraper: Scrape All - No Limit",
"type": "main",
"index": 0
}
],
[
{
"node": "Run Apify Scraper: Scrape All - w/Limit",
"type": "main",
"index": 0
}
]
]
},
"Run Apify Scraper: Scrape 1 URL Only": {
"main": [
[
{
"node": "Clean Data",
"type": "main",
"index": 0
}
]
]
},
"Prepare Settings for Apify Web Scraper": {
"main": [
[
{
"node": "No Limit to Number of Scraped Pages?",
"type": "main",
"index": 0
}
],
[
{
"node": "Run Apify Scraper: Scrape 1 URL Only",
"type": "main",
"index": 0
}
]
]
},
"Run Apify Scraper: Scrape All - w/Limit": {
"main": [
[
{
"node": "Clean Data",
"type": "main",
"index": 0
}
]
]
},
"Run Apify Scraper: Scrape All - No Limit": {
"main": [
[
{
"node": "Clean Data",
"type": "main",
"index": 0
}
]
]
}
}
}
Credentials you'll need
Each integration node will prompt for credentials when you import. We strip credential IDs before publishing — you'll add your own.
googlePalmApisupabaseApi
For the full experience including quality scoring and batch install features for each workflow upgrade to Pro
About this workflow
Convert any website into a searchable vector database for AI chatbots. Submit a URL, choose scraping scope, and this workflow handles everything: scraping, cleaning, chunking, embedding, and storing in Supabase. Scrapes websites using Apify (3 modes: full site unlimited, full…
Source: https://n8n.io/workflows/10565/ — original creator credit. Request a take-down →
Related workflows
Workflows that share integrations, category, or trigger type with this one. All free to copy and import.
n8n telegram RAG. Uses lmChatGoogleGemini, embeddingsGoogleGemini, memoryManager, vectorStoreSupabase. Event-driven trigger; 32 nodes.
An AI-powered sales agent on WhatsApp that handles product inquiries using your Supabase knowledge base and n8n catalog. Customers can send text, voice notes, or images to ask about products, pricing,
This template is designed for podcasters, researchers, educators, product teams, and support teams who work with audio content and want to turn it into searchable knowledge. It is especially useful fo
Firecrawl RAG. Uses embeddingsOpenAi, vectorStoreSupabase, lmChatOpenAi, agent. Event-driven trigger; 13 nodes.
Api Schema Extractor. Uses manualTrigger, httpRequest, splitOut, textSplitterRecursiveCharacterTextSplitter. Event-driven trigger; 88 nodes.