This workflow corresponds to n8n.io template #16540 — we link there as the canonical source.
This workflow follows the Documentdefaultdataloader → Google Drive recipe pattern — see all workflows that pair these two integrations.
The workflow JSON
Copy or download the full n8n JSON below. Paste it into a new n8n workflow, add your credentials, activate. Full import guide →
{
"id": "garXcGwE9KY0NEsG",
"meta": {
"templateCredsSetupCompleted": true
},
"name": "Find Semantic Duplicate Website Pages Using Vector Embeddings",
"tags": [],
"nodes": [
{
"id": "7762adac-3892-4fd3-9552-389767f3e8dc",
"name": "Loop Source File",
"type": "n8n-nodes-base.splitInBatches",
"position": [
768,
336
],
"parameters": {
"options": {},
"batchSize": 10
},
"typeVersion": 3
},
{
"id": "676756a6-7125-4cbe-bad5-de7c88bbd255",
"name": "GDrive Download Document",
"type": "n8n-nodes-base.googleDrive",
"onError": "continueErrorOutput",
"position": [
960,
352
],
"parameters": {
"fileId": {
"__rl": true,
"mode": "id",
"value": "={{ $json.id }}"
},
"options": {},
"operation": "download"
},
"credentials": {
"googleDriveOAuth2Api": {
"name": "<your credential>"
}
},
"typeVersion": 3
},
{
"id": "363147c0-bc0d-47b3-8d2d-4b2093de1b16",
"name": "Extract Raw Text Content",
"type": "n8n-nodes-base.html",
"position": [
1184,
336
],
"parameters": {
"options": {},
"operation": "extractHtmlContent",
"sourceData": "binary",
"extractionValues": {
"values": [
{
"key": "page_text",
"cssSelector": "body",
"skipSelectors": "img, header, footer, nav, aside, menu, dialog, template, script, style, noscript, iframe, svg, canvas, map, object, embed, audio, video, picture, form, button, input, select, textarea, details, [aria-hidden=\"true\"], [hidden], [role=\"dialog\"], [role=\"alert\"], [role=\"banner\"], [role=\"navigation\"], [role=\"contentinfo\"], [role=\"menu\"], [role=\"menubar\"], [role=\"search\"], #onetrust-consent-sdk, #cc-window, #usercentrics-root, .cc-window, .cookie-banner, .cookie-consent, .cookie-notice, [id^=\"cookie-\"], [class^=\"cookie-\"], [id^=\"consent\"], [class^=\"consent\"], .modal, .modal-dialog, .modal-content, .modal-overlay, .popup, .popup-container, .lightbox, .overlay, .ad-slot, .adsbygoogle, [id^=\"div-gpt-ad\"], .taboola-container, .outbrain, .advertisement, [class^=\"ad-container\"], [class^=\"ad-wrapper\"], [class^=\"sponsor\"], .share-buttons, .social-share, .a2a_kit, [class^=\"share-\"], [class^=\"social-\"], #comments, .comments-area, .disqus-thread, .widget, .widget-area, #secondary, #sidebar, .sidebar, .moduletable, .toast, .snackbar, .spinner, .loader, .cmp-share-bar, .cmp-video__cookie-fallback, .cmp-feedback-banner, #target-recommendations-bottom, .cmp-promo-container--single-row-multi-columns, .cmp-skip-navigation-link, .cmp-header__welcome"
}
]
}
},
"typeVersion": 1.2
},
{
"id": "19a3e8bb-5f7a-4757-bded-1a7af69d6a20",
"name": "Save Scraped Page Text",
"type": "n8n-nodes-base.postgres",
"position": [
1584,
336
],
"parameters": {
"query": "CREATE TABLE IF NOT EXISTS scraped_pages (\n sheet_id text PRIMARY KEY,\n file_name text,\n file_url text,\n page_text text\n);\n\nINSERT INTO scraped_pages (\n sheet_id,\n file_name,\n file_url,\n page_text\n)\nVALUES (\n $1,\n $2,\n $3,\n $4\n)\nON CONFLICT (sheet_id)\nDO UPDATE SET\n file_name = EXCLUDED.file_name,\n file_url = EXCLUDED.file_url,\n page_text = EXCLUDED.page_text;",
"options": {
"queryReplacement": "={{\n [\n $json[\"Sheet ID\"],\n $json[\"File Name\"],\n $json[\"File URL\"],\n $json.page_text || \"\"\n ]\n}}"
},
"operation": "executeQuery"
},
"credentials": {
"postgres": {
"name": "<your credential>"
}
},
"typeVersion": 2.6
},
{
"id": "f86c4b3d-8643-486b-acc0-21b6d4740ef8",
"name": "Batches for Embedding",
"type": "n8n-nodes-base.splitInBatches",
"position": [
560,
624
],
"parameters": {
"options": {},
"batchSize": 10
},
"typeVersion": 3
},
{
"id": "874ae205-a2f5-4858-9eb5-48ac7177ba5c",
"name": "Get Unprocessed Scraped Text",
"type": "n8n-nodes-base.postgres",
"position": [
816,
640
],
"parameters": {
"query": "SELECT *\nFROM scraped_pages\nWHERE sheet_id = $1;",
"options": {
"queryReplacement": "={{ $json.id }}"
},
"operation": "executeQuery"
},
"credentials": {
"postgres": {
"name": "<your credential>"
}
},
"typeVersion": 2.6
},
{
"id": "b4ce52ca-6e82-4445-a7bc-a814daa850ba",
"name": "Save Document Embeddings",
"type": "@n8n/n8n-nodes-langchain.vectorStorePGVector",
"position": [
960,
640
],
"parameters": {
"mode": "insert",
"options": {},
"embeddingBatchSize": 3
},
"credentials": {
"postgres": {
"name": "<your credential>"
}
},
"typeVersion": 1.3
},
{
"id": "b3ecee2f-b9bd-4d05-a568-0dbcba70a30d",
"name": "Generate Local Embeddings",
"type": "@n8n/n8n-nodes-langchain.embeddingsOllama",
"onError": "continueRegularOutput",
"position": [
960,
816
],
"parameters": {
"model": "mxbai-embed-large:latest"
},
"credentials": {
"ollamaApi": {
"name": "<your credential>"
}
},
"retryOnFail": true,
"typeVersion": 1
},
{
"id": "5e723b34-3fdc-4489-ab1e-069b02cc09e2",
"name": "Context Injector",
"type": "@n8n/n8n-nodes-langchain.documentDefaultDataLoader",
"position": [
1232,
752
],
"parameters": {
"options": {
"metadata": {
"metadataValues": [
{
"name": "=sheet_id",
"value": "={{ $json.sheet_id }}"
},
{
"name": "file_name",
"value": "={{ $json.file_name }}"
},
{
"name": "file_url",
"value": "={{ $json.file_url }}"
}
]
}
},
"jsonData": "={{ $json.page_text }}",
"jsonMode": "expressionData",
"textSplittingMode": "custom"
},
"typeVersion": 1.1
},
{
"id": "3b8cc06e-4f5c-4d19-ba97-717e04e98442",
"name": "Chunk Text Recursively",
"type": "@n8n/n8n-nodes-langchain.textSplitterRecursiveCharacterTextSplitter",
"position": [
1232,
928
],
"parameters": {
"options": {},
"chunkSize": 500,
"chunkOverlap": 50
},
"typeVersion": 1
},
{
"id": "9facf364-8858-4f67-bcc4-cff7f4a245ba",
"name": "Dedup Processed Items",
"type": "n8n-nodes-base.removeDuplicates",
"onError": "continueErrorOutput",
"position": [
1536,
640
],
"parameters": {
"compare": "selectedFields",
"options": {},
"fieldsToCompare": "metadata.sheet_id"
},
"typeVersion": 2
},
{
"id": "19480d1b-e33e-431e-83b8-2560b856ec69",
"name": "Start Duplicate Check",
"type": "n8n-nodes-base.manualTrigger",
"position": [
-288,
336
],
"parameters": {},
"typeVersion": 1
},
{
"id": "f798029a-d259-4c3e-8f6c-5e8baba8ff32",
"name": "Clear Vector Table",
"type": "n8n-nodes-base.postgres",
"position": [
-48,
336
],
"parameters": {
"table": {
"__rl": true,
"mode": "list",
"value": "n8n_vectors",
"cachedResultName": "n8n_vectors"
},
"schema": {
"__rl": true,
"mode": "list",
"value": "public"
},
"options": {},
"operation": "deleteTable"
},
"credentials": {
"postgres": {
"name": "<your credential>"
}
},
"typeVersion": 2.6
},
{
"id": "fb853085-2c01-48df-8140-a20313d24315",
"name": "Clear Scraped Pages Table",
"type": "n8n-nodes-base.postgres",
"position": [
160,
336
],
"parameters": {
"table": {
"__rl": true,
"mode": "list",
"value": "scraped_pages",
"cachedResultName": "scraped_pages"
},
"schema": {
"__rl": true,
"mode": "list",
"value": "public"
},
"options": {},
"operation": "deleteTable"
},
"credentials": {
"postgres": {
"name": "<your credential>"
}
},
"typeVersion": 2.6
},
{
"id": "3cad7290-54f4-456e-ba99-7f3b39a2718a",
"name": "Scan Source Directory",
"type": "n8n-nodes-base.googleDrive",
"position": [
368,
336
],
"parameters": {
"filter": {
"folderId": {
"__rl": true,
"mode": "url",
"value": "https://drive.google.com/drive/folders/1ejEhBkbwaG20ii4tvKQ6cvhcBXaBngY_?usp=sharing"
}
},
"options": {
"fields": [
"webViewLink",
"id",
"name"
]
},
"resource": "fileFolder",
"returnAll": true
},
"credentials": {
"googleDriveOAuth2Api": {
"name": "<your credential>"
}
},
"typeVersion": 3
},
{
"id": "c8dec740-0d11-4b66-b32b-881229b3778c",
"name": "Isolate Target Documents",
"type": "n8n-nodes-base.filter",
"position": [
560,
336
],
"parameters": {
"options": {},
"conditions": {
"options": {
"version": 3,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "2f4f1f7e-1963-4550-93c8-4039660fd0e3",
"operator": {
"type": "string",
"operation": "exists",
"singleValue": true
},
"leftValue": "={{ $json.name }}",
"rightValue": "original"
}
]
}
},
"typeVersion": 2.3
},
{
"id": "47622167-ef6d-43dd-9188-78c1e2d25ddb",
"name": "Create HNSW Index",
"type": "n8n-nodes-base.postgres",
"position": [
-384,
1120
],
"parameters": {
"query": "DO $$\nDECLARE\n idx_record RECORD;\nBEGIN\n -- 1. Safely find ALL matching indexes specifically in the public schema\n FOR idx_record IN \n SELECT indexname \n FROM pg_indexes \n WHERE schemaname = 'public'\n AND tablename = 'n8n_vectors' \n AND indexname LIKE 'n8n_vectors_embedding_idx%'\n LOOP\n -- 2. Drop ALL of them (it is faster to alter a table without indexes attached)\n EXECUTE 'DROP INDEX IF EXISTS public.' || quote_ident(idx_record.indexname);\n END LOOP;\nEND $$;\n\n-- 3. Apply the 1024-dimension constraint\n-- Warning: If existing rows have vectors that are NOT 1024 dimensions, this will fail.\nALTER TABLE public.n8n_vectors ALTER COLUMN embedding TYPE vector(1024);\n\n-- 4. Create the single, fresh HNSW index safely\nCREATE INDEX IF NOT EXISTS n8n_vectors_embedding_idx \nON public.n8n_vectors USING hnsw (embedding vector_cosine_ops);",
"options": {},
"operation": "executeQuery"
},
"credentials": {
"postgres": {
"name": "<your credential>"
}
},
"executeOnce": true,
"typeVersion": 2.6
},
{
"id": "75ea2adf-e522-450b-a814-8029124f4f4c",
"name": "Compute Chunk Similarities",
"type": "n8n-nodes-base.postgres",
"position": [
-80,
1120
],
"parameters": {
"query": "BEGIN;\n\n-- 1. Expand the index search buffer (Default is 40). \n-- Must be slightly higher than your LIMIT to ensure accurate results.\nSET LOCAL hnsw.ef_search = 550;\n\n-- 2. Force Postgres to trust the index.\n-- This stops the optimizer from flipping to a full-table scan due to the high limit.\nSET LOCAL enable_seqscan = off;\n\n-- 3. Execute the table creation\nDROP TABLE IF EXISTS chunk_matches;\n\nCREATE TABLE chunk_matches AS\nSELECT\n a.metadata->>'file_name' AS page_a,\n b.metadata->>'file_name' AS page_b,\n a.id AS chunk_a_id,\n b.id AS chunk_b_id,\n 1 - (a.embedding <=> b.embedding) AS similarity\nFROM n8n_vectors a\nCROSS JOIN LATERAL (\n SELECT id, embedding, metadata\n FROM n8n_vectors\n WHERE id != a.id\n AND metadata->>'file_name' > a.metadata->>'file_name' \n ORDER BY embedding <=> a.embedding\n LIMIT 500 \n) b\nWHERE (a.embedding <=> b.embedding) < 0.15;\n\nCOMMIT;",
"options": {},
"operation": "executeQuery"
},
"credentials": {
"postgres": {
"name": "<your credential>"
}
},
"executeOnce": true,
"typeVersion": 2.6,
"alwaysOutputData": true
},
{
"id": "11aabe12-36fd-4d31-9ec3-61163fc63ed6",
"name": "Generate Pairwise Report",
"type": "n8n-nodes-base.postgres",
"position": [
160,
1120
],
"parameters": {
"query": "DROP TABLE IF EXISTS pairwise_matrix_report;\n\nCREATE TABLE pairwise_matrix_report AS\nWITH aggregated_pairs AS (\n SELECT \n page_a AS source_page,\n page_b AS target_page,\n COUNT(*) AS total_matched_chunks,\n MAX(similarity) AS max_similarity,\n AVG(similarity) AS avg_similarity\n FROM chunk_matches\n WHERE similarity < 1\n AND page_a < page_b\n GROUP BY page_a, page_b\n HAVING COUNT(*) >= 2\n),\npage_metrics AS (\n SELECT \n v.metadata->>'file_name' AS raw_page_name,\n COUNT(*) AS total_page_chunks\n FROM n8n_vectors v\n GROUP BY v.metadata->>'file_name'\n)\nSELECT \n -- Cleaned Destination URLs\n 'https://' || REPLACE(\n REPLACE(\n REGEXP_REPLACE(ap.source_page, '^(rendered|original)_https_', ''), \n '.html.html', ''\n ), \n '_', '/'\n ) AS source_url,\n \n 'https://' || REPLACE(\n REPLACE(\n REGEXP_REPLACE(ap.target_page, '^(rendered|original)_https_', ''), \n '.html.html', ''\n ), \n '_', '/'\n ) AS target_url,\n \n -- Chunk Match Metrics\n ap.total_matched_chunks,\n ap.max_similarity,\n ap.avg_similarity,\n \n -- Page structural context (Added columns)\n ma.total_page_chunks AS chunks_page_a,\n mb.total_page_chunks AS chunks_page_b,\n \n -- Robust Word Count Calculation\n COALESCE(\n array_length(regexp_split_to_array(trim(sa.page_text), '\\s+'), 1), \n 0\n ) AS word_count_page_a,\n \n COALESCE(\n array_length(regexp_split_to_array(trim(sb.page_text), '\\s+'), 1), \n 0\n ) AS word_count_page_b,\n \n -- Original Ingestion Strings appended at the end\n ap.source_page AS raw_source_page,\n ap.target_page AS raw_target_page\n\nFROM aggregated_pairs ap\n-- Join for Chunk Counts\nLEFT JOIN page_metrics ma ON ap.source_page = ma.raw_page_name\nLEFT JOIN page_metrics mb ON ap.target_page = mb.raw_page_name\n-- Join for Word Counts (Directly to scraped_pages to avoid grouping by text)\nLEFT JOIN scraped_pages sa ON ap.source_page = sa.file_name\nLEFT JOIN scraped_pages sb ON ap.target_page = sb.file_name\n\nORDER BY ap.total_matched_chunks DESC;",
"options": {},
"operation": "executeQuery"
},
"credentials": {
"postgres": {
"name": "<your credential>"
}
},
"typeVersion": 2.6,
"alwaysOutputData": true
},
{
"id": "f2040f29-9fa4-4dcd-915b-7f23aa55cc73",
"name": "Fetch Chunk Similarity Data",
"type": "n8n-nodes-base.postgres",
"position": [
400,
1120
],
"parameters": {
"query": "SELECT * FROM pairwise_matrix_report;",
"options": {},
"operation": "executeQuery"
},
"credentials": {
"postgres": {
"name": "<your credential>"
}
},
"typeVersion": 2.6,
"alwaysOutputData": true
},
{
"id": "587e8b82-7641-4b97-ac5b-edc9db2f14da",
"name": "Export Chunk Similarity Report",
"type": "n8n-nodes-base.convertToFile",
"position": [
656,
1120
],
"parameters": {
"options": {}
},
"typeVersion": 1.1
},
{
"id": "c78c074d-6d60-458a-8970-1fa6f1317a0f",
"name": "Calculate Page Centroids",
"type": "n8n-nodes-base.postgres",
"position": [
928,
1120
],
"parameters": {
"query": "DROP TABLE IF EXISTS public.page_centroids;\n\nCREATE TABLE public.page_centroids (\n page_url TEXT PRIMARY KEY,\n centroid_embedding VECTOR(1024)\n);",
"options": {},
"operation": "executeQuery"
},
"credentials": {
"postgres": {
"name": "<your credential>"
}
},
"typeVersion": 2.6
},
{
"id": "bfcb7408-2cdd-4db2-af84-a8bc2c44de63",
"name": "Compute Centroid Distances",
"type": "n8n-nodes-base.postgres",
"position": [
1136,
1120
],
"parameters": {
"query": "INSERT INTO public.page_centroids (page_url, centroid_embedding)\nSELECT \n metadata->>'file_name' AS page_url,\n AVG(embedding)::vector(1024) AS centroid_embedding\nFROM public.n8n_vectors\nWHERE metadata->>'file_name' IS NOT NULL\nGROUP BY metadata->>'file_name';",
"options": {},
"operation": "executeQuery"
},
"credentials": {
"postgres": {
"name": "<your credential>"
}
},
"typeVersion": 2.6
},
{
"id": "88e12cef-5c14-4588-9db7-75a1e84fa62a",
"name": "Aggregate Page-Level Metrics",
"type": "n8n-nodes-base.postgres",
"position": [
1360,
1120
],
"parameters": {
"query": "DO $$\nDECLARE\n idx_record RECORD;\nBEGIN\n FOR idx_record IN \n SELECT indexname \n FROM pg_indexes \n WHERE schemaname = 'public'\n AND tablename = 'page_centroids' \n AND indexname LIKE 'page_centroids_embedding_idx%'\n LOOP\n EXECUTE 'DROP INDEX IF EXISTS public.' || quote_ident(idx_record.indexname);\n END LOOP;\nEND $$;\n\nCREATE INDEX IF NOT EXISTS page_centroids_embedding_idx \nON public.page_centroids USING hnsw (centroid_embedding vector_cosine_ops);",
"options": {},
"operation": "executeQuery"
},
"credentials": {
"postgres": {
"name": "<your credential>"
}
},
"typeVersion": 2.6
},
{
"id": "41ee492e-c5bd-44fc-9119-2cef989a8514",
"name": "Finalize Duplicate Flags",
"type": "n8n-nodes-base.postgres",
"position": [
1584,
1120
],
"parameters": {
"query": "BEGIN;\n\nDROP TABLE IF EXISTS public.page_matches;\n\nCREATE TABLE public.page_matches AS\nSELECT\n a.page_url AS page_a,\n b.page_url AS page_b,\n 1 - (a.centroid_embedding <=> b.centroid_embedding) AS similarity\nFROM public.page_centroids a\nINNER JOIN public.page_centroids b \n ON b.page_url > a.page_url\nWHERE (a.centroid_embedding <=> b.centroid_embedding) < 0.05;\n\nCOMMIT;",
"options": {},
"operation": "executeQuery"
},
"credentials": {
"postgres": {
"name": "<your credential>"
}
},
"typeVersion": 2.6
},
{
"id": "f71aff68-85e6-4165-be93-7cc3c6d900a2",
"name": "Fetch Page-Level Report Data",
"type": "n8n-nodes-base.postgres",
"position": [
1776,
1120
],
"parameters": {
"query": "SELECT \n -- Cleaned Destination URLs\n 'https://' || REPLACE(\n REPLACE(\n REGEXP_REPLACE(page_a, '^(rendered|original)_https_', ''), \n '.html.html', ''\n ), \n '_', '/'\n ) AS source_url,\n \n 'https://' || REPLACE(\n REPLACE(\n REGEXP_REPLACE(page_b, '^(rendered|original)_https_', ''), \n '.html.html', ''\n ), \n '_', '/'\n ) AS target_url,\n \n -- Score\n similarity AS score,\n \n -- Original Ingestion Strings\n page_a,\n page_b\n\nFROM page_matches;",
"options": {},
"operation": "executeQuery"
},
"credentials": {
"postgres": {
"name": "<your credential>"
}
},
"typeVersion": 2.6,
"alwaysOutputData": true
},
{
"id": "22cece4e-ef4a-4ee0-b2d4-f42e101e5869",
"name": "Export Page-Level Report",
"type": "n8n-nodes-base.convertToFile",
"position": [
1968,
1120
],
"parameters": {
"options": {}
},
"typeVersion": 1.1
},
{
"id": "930c36c0-129b-472a-b923-2f52321cca09",
"name": "Format Database Payload",
"type": "n8n-nodes-base.set",
"position": [
1392,
336
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "1651963f-1f61-4bc9-9094-9a4fdb7a6cc9",
"name": "page_text",
"type": "string",
"value": "={{ $json.page_text.replace(/\\[.*?\\]|(?:https?:\\/\\/|\\/)[^\\s]+/g, '').replace(/Read more|Learn more|-{3,}/gi, '').replace(/\\n{2,}/g, '\\n').trim() }}"
},
{
"id": "e73e6114-8163-480a-a906-dde256f243d4",
"name": "Sheet ID",
"type": "string",
"value": "={{ $('Loop Source File').item.json.id }}"
},
{
"id": "9a1c9bf0-da2c-48dd-971d-537821fdd06a",
"name": "File Name",
"type": "string",
"value": "={{ $('Loop Source File').item.json.name }}"
},
{
"id": "1ad52726-b290-4406-9e08-f46b1cbcdddb",
"name": "File URL",
"type": "string",
"value": "={{ $('Loop Source File').item.json.webViewLink }}"
}
]
}
},
"typeVersion": 3.4
},
{
"id": "4f6e5f19-82d5-4e38-83a5-9124f196c186",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
320,
160
],
"parameters": {
"color": 3,
"width": 192,
"height": 304,
"content": "Input your Drive Folder containing Source or Rendered HTML files here.\n\nLimit files to 1000 or 1500. If you have good system specs, you can analyse more files."
},
"typeVersion": 1
},
{
"id": "bafb3654-db46-4f96-b47e-e4ad6be37f48",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
-416,
144
],
"parameters": {
"color": 7,
"width": 1104,
"height": 368,
"content": "## Phase 1: Ingestion & Storage\n- Trigger the automated duplicate check execution.\n- Purge existing records from the vector database table.\n- Delete legacy data from the scraped pages tracking table.\n- Query the specified Google Drive directory to retrieve file listings.\n- Filter the retrieved files to isolate valid target documents for downstream processing."
},
"typeVersion": 1
},
{
"id": "1f418266-9a42-4268-b9d3-3ade476a8584",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
704,
144
],
"parameters": {
"color": 7,
"width": 1264,
"height": 400,
"content": "## Phase 2 - Content Extraction & Storage\n- Distribute isolated target files into batches for processing.\n- Loop through the source files using parallel worker nodes.\n- Download raw document files directly from Google Drive.\n- Extract plain text content from the downloaded HTML files.\n- Format the extracted text into database-ready payloads.\n- Save the structured text to the scraped pages and helper tables."
},
"typeVersion": 1
},
{
"id": "d31f8abe-7745-4249-9806-e6cf3ab22ce5",
"name": "Sticky Note3",
"type": "n8n-nodes-base.stickyNote",
"position": [
-240,
592
],
"parameters": {
"color": 7,
"width": 1952,
"height": 480,
"content": "## Phase 3: Embedding Generation & Chunking\n- Retrieve unprocessed scraped text payloads in configurable batches.\n- Split the raw text recursively into semantic chunks for vectorization.\n- Generate local vector embeddings for each isolated text chunk across distributed workers.\n- Record the generated embeddings and deduplicate items to maintain data integrity."
},
"typeVersion": 1
},
{
"id": "a167cdeb-8099-4e7d-aeec-5d2e422f6933",
"name": "Sticky Note4",
"type": "n8n-nodes-base.stickyNote",
"position": [
-496,
1104
],
"parameters": {
"color": 7,
"width": 2640,
"height": 368,
"content": "\n\n\n\n\n\n\n\n\n\n\n\n## Phase 4: Similarity Analysis & Export\n- Construct an HNSW index within the database to enable efficient vector similarity searches.\n- Calculate similarity distances between individual text chunks.\n- Compute geometric centroids for page-level text chunk distributions to determine overall document distances.\n- Aggregate the chunk and centroid metrics to assign final duplicate classification flags.\n- Extract the finalized datasets and convert them into downloadable CSV reports."
},
"typeVersion": 1
},
{
"id": "0e57306b-a1cb-413c-ad90-25d7b736457c",
"name": "Sticky Note5",
"type": "n8n-nodes-base.stickyNote",
"position": [
-880,
144
],
"parameters": {
"width": 432,
"height": 928,
"content": "## Semantic Duplicate Checker\n### Process source documents to extract text, generate vector embeddings, and compute similarity metrics to identify duplicate pages.\n\n\nThis workflow scans a Google Drive source directory for website page documents, extracts each page\u2019s text, stores the scraped content in Postgres, and then creates vector embeddings for the text chunks using Ollama and PGVector. After embeddings are generated, it builds an HNSW index, computes chunk-level and page-level semantic similarity metrics, flags likely duplicate pages, and exports reports for review.\n\n### Setup steps\n\n- Configure Google Drive credentials and set the source folder or directory used by the scan and download nodes.\n- Configure Postgres credentials and ensure the database has pgvector enabled plus the required scraped-pages, vector, similarity, and report tables or SQL objects referenced by the query nodes.\n- Configure the Ollama embeddings node with a locally available embedding model and ensure the Ollama service is reachable from n8n.\n- Review the SQL in the cleanup, embedding, similarity, centroid, aggregation, and reporting nodes so table names, thresholds, and index definitions match your database schema.\n- Set or verify the document filter criteria, text extraction settings, chunking parameters, and export file formats before running the manual trigger.\n\n### Requirements\n- Google Drive credentials\n- Database with vector and HNSW index support\n- Local embedding models"
},
"typeVersion": 1
},
{
"id": "24b8a598-ef80-469d-afd6-72433f55dae2",
"name": "Sticky Note6",
"type": "n8n-nodes-base.stickyNote",
"position": [
576,
1104
],
"parameters": {
"height": 320,
"content": "\n\n\n\n\n\n\n\n\n\n\n\n\n\nDownload your chunk level matched page similarity report here"
},
"typeVersion": 1
},
{
"id": "c1d0e229-7183-4ac3-af78-1a7d4d8221e5",
"name": "Sticky Note7",
"type": "n8n-nodes-base.stickyNote",
"position": [
1888,
1104
],
"parameters": {
"height": 320,
"content": "\n\n\n\n\n\n\n\n\n\n\n\n\n\nDownload you overall page level similarity report here"
},
"typeVersion": 1
},
{
"id": "0ee0c51f-801b-459d-95f8-470ca31a4fc8",
"name": "Sticky Note10",
"type": "n8n-nodes-base.stickyNote",
"position": [
144,
-128
],
"parameters": {
"width": 544,
"height": 288,
"content": "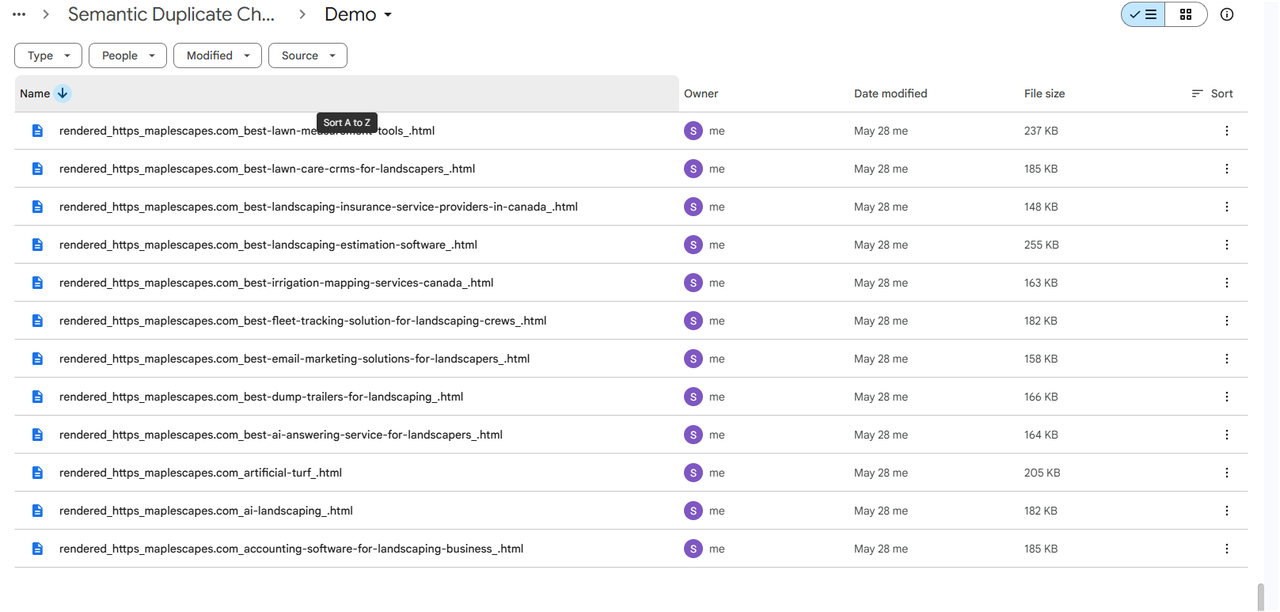\n"
},
"typeVersion": 1
},
{
"id": "b9ab12c6-05c9-4cba-88c6-69aa0dce5b6b",
"name": "Code in JavaScript",
"type": "n8n-nodes-base.code",
"position": [
1776,
336
],
"parameters": {
"jsCode": "// Get all items from the source node\nconst sourceItems = $('Loop Source File').all();\n\n// Map to individual items\nreturn sourceItems.map(item => {\n return {\n json: {\n id: item.json.id\n }\n };\n});"
},
"typeVersion": 2
}
],
"active": false,
"settings": {
"binaryMode": "separate",
"callerPolicy": "workflowsFromSameOwner",
"timeSavedMode": "fixed",
"availableInMCP": false,
"executionOrder": "v1",
"saveManualExecutions": false,
"saveExecutionProgress": false,
"saveDataErrorExecution": "all",
"saveDataSuccessExecution": "none"
},
"versionId": "25b31e2d-79d3-4adf-a7ca-5e9d8b6b0400",
"connections": {
"Context Injector": {
"ai_document": [
[
{
"node": "Save Document Embeddings",
"type": "ai_document",
"index": 0
}
]
]
},
"Loop Source File": {
"main": [
[
{
"node": "Batches for Embedding",
"type": "main",
"index": 0
}
],
[
{
"node": "GDrive Download Document",
"type": "main",
"index": 0
}
]
]
},
"Create HNSW Index": {
"main": [
[
{
"node": "Compute Chunk Similarities",
"type": "main",
"index": 0
}
]
]
},
"Clear Vector Table": {
"main": [
[
{
"node": "Clear Scraped Pages Table",
"type": "main",
"index": 0
}
]
]
},
"Code in JavaScript": {
"main": [
[
{
"node": "Loop Source File",
"type": "main",
"index": 0
}
]
]
},
"Batches for Embedding": {
"main": [
[
{
"node": "Create HNSW Index",
"type": "main",
"index": 0
}
],
[
{
"node": "Get Unprocessed Scraped Text",
"type": "main",
"index": 0
}
]
]
},
"Dedup Processed Items": {
"main": [
[
{
"node": "Batches for Embedding",
"type": "main",
"index": 0
}
],
[
{
"node": "Batches for Embedding",
"type": "main",
"index": 0
}
]
]
},
"Scan Source Directory": {
"main": [
[
{
"node": "Isolate Target Documents",
"type": "main",
"index": 0
}
]
]
},
"Start Duplicate Check": {
"main": [
[
{
"node": "Clear Vector Table",
"type": "main",
"index": 0
}
]
]
},
"Chunk Text Recursively": {
"ai_textSplitter": [
[
{
"node": "Context Injector",
"type": "ai_textSplitter",
"index": 0
}
]
]
},
"Save Scraped Page Text": {
"main": [
[
{
"node": "Code in JavaScript",
"type": "main",
"index": 0
}
]
]
},
"Format Database Payload": {
"main": [
[
{
"node": "Save Scraped Page Text",
"type": "main",
"index": 0
}
]
]
},
"Calculate Page Centroids": {
"main": [
[
{
"node": "Compute Centroid Distances",
"type": "main",
"index": 0
}
]
]
},
"Extract Raw Text Content": {
"main": [
[
{
"node": "Format Database Payload",
"type": "main",
"index": 0
}
]
]
},
"Finalize Duplicate Flags": {
"main": [
[
{
"node": "Fetch Page-Level Report Data",
"type": "main",
"index": 0
}
]
]
},
"GDrive Download Document": {
"main": [
[
{
"node": "Extract Raw Text Content",
"type": "main",
"index": 0
}
],
[]
]
},
"Generate Pairwise Report": {
"main": [
[
{
"node": "Fetch Chunk Similarity Data",
"type": "main",
"index": 0
}
]
]
},
"Isolate Target Documents": {
"main": [
[
{
"node": "Loop Source File",
"type": "main",
"index": 0
}
]
]
},
"Save Document Embeddings": {
"main": [
[
{
"node": "Dedup Processed Items",
"type": "main",
"index": 0
}
]
]
},
"Clear Scraped Pages Table": {
"main": [
[
{
"node": "Scan Source Directory",
"type": "main",
"index": 0
}
]
]
},
"Generate Local Embeddings": {
"ai_embedding": [
[
{
"node": "Save Document Embeddings",
"type": "ai_embedding",
"index": 0
}
]
]
},
"Compute Centroid Distances": {
"main": [
[
{
"node": "Aggregate Page-Level Metrics",
"type": "main",
"index": 0
}
]
]
},
"Compute Chunk Similarities": {
"main": [
[
{
"node": "Generate Pairwise Report",
"type": "main",
"index": 0
}
]
]
},
"Fetch Chunk Similarity Data": {
"main": [
[
{
"node": "Export Chunk Similarity Report",
"type": "main",
"index": 0
}
]
]
},
"Aggregate Page-Level Metrics": {
"main": [
[
{
"node": "Finalize Duplicate Flags",
"type": "main",
"index": 0
}
]
]
},
"Fetch Page-Level Report Data": {
"main": [
[
{
"node": "Export Page-Level Report",
"type": "main",
"index": 0
}
]
]
},
"Get Unprocessed Scraped Text": {
"main": [
[
{
"node": "Save Document Embeddings",
"type": "main",
"index": 0
}
]
]
},
"Export Chunk Similarity Report": {
"main": [
[
{
"node": "Calculate Page Centroids",
"type": "main",
"index": 0
}
]
]
}
}
}
Credentials you'll need
Each integration node will prompt for credentials when you import. We strip credential IDs before publishing — you'll add your own.
googleDriveOAuth2ApiollamaApipostgres
For the full experience including quality scoring and batch install features for each workflow upgrade to Pro
About this workflow
This workflow scans HTML files in a Google Drive folder, extracts and stores page text in Postgres, generates local vector embeddings with Ollama, and uses PGVector similarity searches to produce CSV reports that flag semantically duplicate website pages. Starts manually and…
Source: https://n8n.io/workflows/16540/ — original creator credit. Request a take-down →
Related workflows
Workflows that share integrations, category, or trigger type with this one. All free to copy and import.
RAG AI Agent Template V5. Uses lmChatOpenAi, documentDefaultDataLoader, embeddingsOpenAi, googleDrive. Event-driven trigger; 56 nodes.
Agente AI RAG. Uses lmChatOpenAi, documentDefaultDataLoader, embeddingsOpenAi, googleDrive. Event-driven trigger; 42 nodes.
This powerful AI automation add-on upgrades your Telegram Bot Starter Template by integrating a fully functional AI chatbot and a context-aware AI agent that answers user questions using your internal
Contextual Retrieval. Uses lmChatOpenAi, documentDefaultDataLoader, embeddingsOpenAi, googleDrive. Event-driven trigger; 24 nodes.
Gmail to Vector Embeddings with PGVector and Ollama. Uses embeddingsOllama, documentDefaultDataLoader, textSplitterRecursiveCharacterTextSplitter, gmailTrigger. Event-driven trigger; 20 nodes.