This workflow corresponds to n8n.io template #5436 — we link there as the canonical source.
This workflow follows the Chat Trigger → HTTP Request recipe pattern — see all workflows that pair these two integrations.
The workflow JSON
Copy or download the full n8n JSON below. Paste it into a new n8n workflow, add your credentials, activate. Full import guide →
{
"meta": {
"templateCredsSetupCompleted": true
},
"nodes": [
{
"id": "3634e7f6-9c01-48f6-9ed0-b4c9514b134e",
"name": "Database retrieval1",
"type": "@n8n/n8n-nodes-langchain.toolCode",
"position": [
-100,
460
],
"parameters": {
"name": "knowledge_base",
"jsCode": "const axios = require('axios');\n\nconst OPENAI_API_KEY = '<openai_api_token>';\nconst SUPABASE_URL = 'https://<supabase_id>.supabase.co';\nconst SUPABASE_API_KEY = '<supabase_api_token>';\n\n\n// Get input from the previous node\nconst queryText = query.query;\nconst filters = $('Aggregate files').item.json || {}; // Should include { file_id: [\"uuid1\", \"uuid2\"] }\n\nasync function getEmbedding(text) {\n if (!text || typeof text !== 'string') {\n throw new Error(`Invalid input for embedding: \"${text}\"`);\n }\n\n try {\n console.log(\"\ud83d\udd39 Generating embedding for query:\", text);\n const response = await axios.post(\n 'https://api.openai.com/v1/embeddings',\n { input: text, model: 'text-embedding-3-small' },\n {\n headers: {\n 'Content-Type': 'application/json',\n 'Authorization': `Bearer ${OPENAI_API_KEY}`\n }\n }\n );\n\n console.log(\"\u2705 OpenAI Embedding Generated Successfully!\");\n return response.data.data[0].embedding;\n } catch (error) {\n console.error(\"\u274c OpenAI Embedding Error:\", error.response?.data || error.message);\n throw new Error(`OpenAI Embedding Error: ${JSON.stringify(error.response?.data || error.message)}`);\n }\n}\n\nasync function fetchDocuments(queryEmbedding) {\n try {\n console.log(\"\ud83d\udd39 Sending request to Supabase...\");\n console.log(\"\ud83d\udd39 Query Embedding Length:\", queryEmbedding.length);\n console.log(\"\ud83d\udd39 Filters used:\", JSON.stringify(filters, null, 2));\n\n const response = await axios.post(\n `${SUPABASE_URL}/rest/v1/rpc/match_documents`,\n {\n query_embedding: queryEmbedding,\n match_count: 5,\n filter: filters\n },\n {\n headers: {\n 'Content-Type': 'application/json',\n 'apikey': SUPABASE_API_KEY,\n 'Authorization': `Bearer ${SUPABASE_API_KEY}`\n }\n }\n );\n\n console.log(\"\u2705 Supabase Response:\", response.data);\n return response.data;\n } catch (error) {\n console.error(\"\u274c Supabase Query Error:\", error.response?.data || error.message);\n throw new Error(`Supabase Query Error: ${error.message}`);\n }\n}\n\nasync function processQuery() {\n try {\n console.log(\"\ud83d\udd39 Processing Query:\", queryText);\n console.log(\"\ud83d\udd39 Filters:\", filters);\n console.log(\"\ud83d\udd0e queryText:\", JSON.stringify(queryText));\n\n const embedding = await getEmbedding(queryText);\n const results = await fetchDocuments(embedding);\n\n // Format results with file name and URL\n const formattedResults = results.map(item => ({\n id: item.id,\n content: item.content,\n similarity: item.similarity.toFixed(4),\n fileName: item.file_name,\n fileUrl: item.file_url\n }));\n\n // Combine content into a single string with file metadata\n const joinedContent = formattedResults.map(item => {\n return `\ud83d\udcc4 *${item.fileName || \"Unnamed file\"}* (${item.similarity} similarity)\\n\ud83d\udd17 ${item.fileUrl || \"No link\"}\\n\\n${item.content}`;\n }).join(\"\\n\\n---\\n\\n\");\n\n console.log(\"\u2705 Final Formatted Results:\", formattedResults);\n console.log(\"\u2705 Final Joined Content:\", joinedContent);\n\n return joinedContent;\n } catch (error) {\n console.error(\"\u274c Processing Error:\", error.message);\n throw new Error(`Processing Error: ${error.message}`);\n }\n}\n\nreturn processQuery();",
"jsonSchemaExample": "{\n\t\"query\": \"n8n\"\n}",
"specifyInputSchema": true
},
"typeVersion": 1.1
},
{
"id": "43eee475-c154-4baf-a3bd-f0c1ef0c3b5c",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-240,
-100
],
"parameters": {
"content": "### Match_documents function\n\ncreate or replace function match_documents(\n query_embedding vector(1536),\n match_count int default null,\n filter jsonb default '{}'\n)\nreturns table (\n id bigint,\n content text,\n similarity float,\n file_name text,\n file_url text\n)\nlanguage plpgsql\nas $$\ndeclare\n filter_conditions text := '';\n file_id_list text[] := '{}';\nbegin\n -- Extract file_id values from filter\n if filter ? 'file_id' then\n select array_agg(value::text)\n into file_id_list\n from jsonb_array_elements_text(filter->'file_id');\n end if;\n\n -- Add file_id filter condition\n if array_length(file_id_list, 1) > 0 then\n filter_conditions := ' AND (d.metadata->>''file_id'') = ANY($3)';\n end if;\n\n -- Run the query with JOIN to files\n return query execute format(\n 'SELECT\n d.id,\n d.content,\n 1 - (d.embedding <=> $1) as similarity,\n f.name as file_name,\n f.google_drive_url as file_url\n FROM documents d\n JOIN files f ON (d.metadata->>''file_id'') = f.id::text\n WHERE true %s\n ORDER BY d.embedding <=> $1\n LIMIT $2',\n filter_conditions\n )\n using query_embedding, match_count, file_id_list;\nend;\n$$;"
},
"typeVersion": 1
},
{
"id": "ad163ed4-c900-4958-aaeb-b9d330e7c77a",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
-840,
520
],
"parameters": {
"content": "### Match_files function\n\ncreate function match_files (\n query_embedding vector(1536),\n match_count int default null,\n filter jsonb default '{}'\n)\nreturns table (\n id uuid,\n description text,\n similarity float\n)\nlanguage plpgsql\nas $$\nbegin\n return query\n select\n f.id,\n f.description,\n 1 - (f.embedding <=> query_embedding) as similarity\n from public.files f\n where filter = '{}' or to_jsonb(f) @> filter\n order by f.embedding <=> query_embedding\n limit match_count;\nend;\n$$;"
},
"typeVersion": 1
},
{
"id": "723564a3-0417-49ac-b280-af3b3fee2d15",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
-840,
720
],
"parameters": {
"height": 140,
"content": "### Files table\n\ncreate table public.files (\n id uuid not null default gen_random_uuid (),\n name text null,\n category text null,\n date_created timestamp with time zone null default (now() AT TIME ZONE 'utc'::text),\n google_drive_url text null,\n theme text null,\n description text null,\n embedding extensions.vector null,\n google_drive_id text null,\n status text null default 'ready'::text,\n type public.file_type null,\n video_transcription_url text null,\n constraint files_pkey primary key (id)\n) TABLESPACE pg_default;"
},
"typeVersion": 1
},
{
"id": "0250b36b-7a91-44b6-a084-f6536689c984",
"name": "When chat message received",
"type": "@n8n/n8n-nodes-langchain.chatTrigger",
"position": [
-960,
280
],
"parameters": {
"options": {}
},
"typeVersion": 1.1
},
{
"id": "343ba375-41ee-474e-968b-ca8e3da5f2f9",
"name": "OpenAI",
"type": "@n8n/n8n-nodes-langchain.openAi",
"position": [
-260,
280
],
"parameters": {
"modelId": {
"__rl": true,
"mode": "list",
"value": "gpt-4.1-mini",
"cachedResultName": "GPT-4.1-MINI"
},
"options": {},
"messages": {
"values": [
{
"content": "={{ $('When chat message received').item.json.chatInput }}"
},
{
"role": "system",
"content": "IMPORTANT Always use knowledge_base tool to retrieve data for answering.\nIMPORTANT Always return url of file as reference if exists."
}
]
}
},
"credentials": {
"openAiApi": {
"name": "<your credential>"
}
},
"typeVersion": 1.8
},
{
"id": "fdd481bc-3b33-43ec-b33c-05b4adbd66c4",
"name": "GetFile",
"type": "n8n-nodes-base.supabase",
"position": [
-740,
1080
],
"parameters": {
"tableId": "files",
"matchType": "allFilters",
"operation": "getAll",
"returnAll": true
},
"credentials": {
"supabaseApi": {
"name": "<your credential>"
}
},
"executeOnce": false,
"typeVersion": 1,
"alwaysOutputData": true
},
{
"id": "f1f1c78e-5aaa-483e-b124-024a5b086561",
"name": "UpdateEmbedding",
"type": "n8n-nodes-base.supabase",
"position": [
-380,
1080
],
"parameters": {
"filters": {
"conditions": [
{
"keyName": "id",
"keyValue": "={{ $('GetFile').item.json.id }}",
"condition": "eq"
}
]
},
"tableId": "files",
"fieldsUi": {
"fieldValues": [
{
"fieldId": "embedding",
"fieldValue": "={{ $json.data[0].embedding }}"
}
]
},
"operation": "update"
},
"credentials": {
"supabaseApi": {
"name": "<your credential>"
}
},
"typeVersion": 1
},
{
"id": "451aceee-bcee-4247-9fb0-9c3048e302a1",
"name": "OpenAI CreateEmbeddings",
"type": "n8n-nodes-base.httpRequest",
"position": [
-560,
1080
],
"parameters": {
"url": "=https://api.openai.com/v1/embeddings",
"method": "POST",
"options": {},
"jsonBody": "={\n \"model\": \"text-embedding-3-small\",\n \"input\": {{JSON.stringify( \"File Name:\" + $json.name + \"Description:\" + $json.description )}} \n }",
"sendBody": true,
"specifyBody": "json",
"authentication": "predefinedCredentialType",
"nodeCredentialType": "openAiApi"
},
"credentials": {
"openAiApi": {
"name": "<your credential>"
}
},
"typeVersion": 4.2
},
{
"id": "657334f2-80e0-402b-b150-52145fa81a69",
"name": "When clicking \u2018Execute workflow\u2019",
"type": "n8n-nodes-base.manualTrigger",
"position": [
-920,
1080
],
"parameters": {},
"typeVersion": 1
},
{
"id": "0420cc67-cd8c-492b-89ed-44912106d3e3",
"name": "Find Files",
"type": "n8n-nodes-base.code",
"position": [
-780,
280
],
"parameters": {
"jsCode": "const axios = require('axios');\n\nconst OPENAI_API_KEY = '<openai_api_token>';\nconst SUPABASE_URL = 'https://<supabase_id>.supabase.co';\nconst SUPABASE_API_KEY = '<supabase_api_token>';\n\n\n// Get input from the previous node\nconst queryText = $('When chat message received').item.json.chatInput ;\nconst filters = {}; // Dynamic filter object\n\nasync function getEmbedding(text) {\n try {\n console.log(\"\ud83d\udd39 Generating embedding for query:\", text);\n const response = await axios.post(\n 'https://api.openai.com/v1/embeddings',\n { input: text, model: 'text-embedding-3-small' },\n {\n headers: {\n 'Content-Type': 'application/json',\n 'Authorization': `Bearer ${OPENAI_API_KEY}`\n }\n }\n );\n\n console.log(\"\u2705 OpenAI Embedding Generated Successfully!\");\n return response.data.data[0].embedding;\n } catch (error) {\n console.error(\"\u274c OpenAI Embedding Error:\", error.response?.data || error.message);\n throw new Error(`OpenAI Embedding Error: ${error.message}`);\n }\n}\n\nasync function fetchFiles(queryEmbedding) {\n try {\n console.log(\"\ud83d\udd39 Sending request to Supabase (match_files)...\");\n console.log(\"\ud83d\udd39 Query Embedding Length:\", queryEmbedding.length);\n console.log(\"\ud83d\udd39 Filters used:\", JSON.stringify(filters, null, 2));\n\n const response = await axios.post(\n `${SUPABASE_URL}/rest/v1/rpc/match_files`,\n {\n query_embedding: queryEmbedding,\n match_count: 5,\n filter: filters\n },\n {\n headers: {\n 'Content-Type': 'application/json',\n 'apikey': SUPABASE_API_KEY,\n 'Authorization': `Bearer ${SUPABASE_API_KEY}`\n }\n }\n );\n\n console.log(\"\u2705 Supabase Response:\", response.data);\n return response.data;\n } catch (error) {\n console.error(\"\u274c Supabase Query Error:\", error.response?.data || error.message);\n throw new Error(`Supabase Query Error: ${error.message}`);\n }\n}\n\nasync function processQuery() {\n try {\n console.log(\"\ud83d\udd39 Processing Query:\", queryText);\n console.log(\"\ud83d\udd39 Filters:\", filters);\n\n const embedding = await getEmbedding(queryText);\n const results = await fetchFiles(embedding);\n\n const formattedResults = results.map(item => ({\n id: item.id,\n description: item.description,\n similarity: item.similarity\n }));\n return formattedResults;\n } catch (error) {\n console.error(\"\u274c Processing Error:\", error.message);\n throw new Error(`Processing Error: ${error.message}`);\n }\n}\n\n// Execute and return results\nreturn processQuery();"
},
"typeVersion": 2
},
{
"id": "b29ed780-bf05-4069-b5e5-257472a4cd8a",
"name": "Filter similarity",
"type": "n8n-nodes-base.filter",
"position": [
-620,
280
],
"parameters": {
"options": {},
"conditions": {
"options": {
"version": 2,
"leftValue": "",
"caseSensitive": true,
"typeValidation": "strict"
},
"combinator": "and",
"conditions": [
{
"id": "a9268663-5051-4cb3-a51c-c77fd81d5135",
"operator": {
"type": "number",
"operation": "gt"
},
"leftValue": "={{ $(\"Find Files\").item.json[\"similarity\"] }}",
"rightValue": 0.2
}
]
}
},
"typeVersion": 2.2
},
{
"id": "81875856-45a0-48ee-95a6-10cc640eea9f",
"name": "Aggregate files",
"type": "n8n-nodes-base.aggregate",
"position": [
-440,
280
],
"parameters": {
"options": {},
"fieldsToAggregate": {
"fieldToAggregate": [
{
"renameField": true,
"outputFieldName": "file_id",
"fieldToAggregate": "id"
}
]
}
},
"typeVersion": 1
},
{
"id": "17f29fea-6b0d-477c-9e9c-53ed5e896c72",
"name": "Set Output",
"type": "n8n-nodes-base.set",
"position": [
100,
280
],
"parameters": {
"options": {},
"assignments": {
"assignments": [
{
"id": "db940cb7-dc10-4b53-a310-53d15e9f2feb",
"name": "output",
"type": "string",
"value": "={{ $json.message.content }}"
}
]
}
},
"typeVersion": 3.4
},
{
"id": "ea9cfacd-4e01-4809-9da0-afd8c58c3689",
"name": "Sticky Note3",
"type": "n8n-nodes-base.stickyNote",
"position": [
-240,
80
],
"parameters": {
"height": 140,
"content": "### Documents table\n\n-- Enable the pgvector extension to work with embedding vectors\ncreate extension vector;\n\n-- Create a table to store your documents\ncreate table documents (\n id bigserial primary key,\n content text, -- corresponds to Document.pageContent\n metadata jsonb, -- corresponds to Document.metadata\n embedding vector(1536) -- 1536 works for OpenAI embeddings, change if needed\n);"
},
"typeVersion": 1
},
{
"id": "018eb8c5-7504-4e99-92a9-2cd0ef0ab9de",
"name": "Sticky Note4",
"type": "n8n-nodes-base.stickyNote",
"position": [
-660,
420
],
"parameters": {
"width": 180,
"height": 80,
"content": "Change similarity to get less/more results"
},
"typeVersion": 1
},
{
"id": "1c56abbb-fe0a-478c-9bbf-d77484d885be",
"name": "Sticky Note5",
"type": "n8n-nodes-base.stickyNote",
"position": [
-840,
140
],
"parameters": {
"width": 200,
"height": 100,
"content": "### Replace Supabase and OpenAI credentials"
},
"typeVersion": 1
},
{
"id": "6076f007-7ec7-400c-849c-1adee9e11a5d",
"name": "Sticky Note6",
"type": "n8n-nodes-base.stickyNote",
"position": [
-160,
720
],
"parameters": {
"width": 220,
"height": 120,
"content": "Change match_count variable (5 default) to increase/decrease number of returned vectors"
},
"typeVersion": 1
},
{
"id": "81689d9a-8702-467f-bab0-9295385fcd1c",
"name": "Sticky Note7",
"type": "n8n-nodes-base.stickyNote",
"position": [
-840,
20
],
"parameters": {
"width": 200,
"height": 100,
"content": "Change match_count variable (5 default) to increase/decrease number of returned files"
},
"typeVersion": 1
},
{
"id": "8cf014f1-8796-46dc-8077-8cf442bebcf8",
"name": "Sticky Note8",
"type": "n8n-nodes-base.stickyNote",
"position": [
-160,
600
],
"parameters": {
"width": 200,
"height": 100,
"content": "### Replace Supabase and OpenAI credentials"
},
"typeVersion": 1
},
{
"id": "3acda68c-af77-41ad-aaae-6c08f4220aaf",
"name": "Sticky Note9",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1040,
-180
],
"parameters": {
"color": 5,
"width": 1360,
"height": 1160,
"content": "## Main workflow"
},
"typeVersion": 1
},
{
"id": "2453f44d-f01f-45bc-8273-eaa0cd5da858",
"name": "Sticky Note10",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1040,
1000
],
"parameters": {
"color": 5,
"width": 880,
"height": 300,
"content": "## Files description embedding workflow"
},
"typeVersion": 1
},
{
"id": "f9bea260-c665-41ab-aec7-99f094f3e0f7",
"name": "Sticky Note11",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1720,
-180
],
"parameters": {
"color": 7,
"width": 636.2128494576581,
"height": 497.1532689930921,
"content": "\n## AI Agent To Chat With Files In Supabase Storage\n**Made by [Mark Shcherbakov](https://www.linkedin.com/in/marklowcoding/) from community [5minAI](https://www.skool.com/5minai-pro)**\n\nManually searching and reviewing info across many documents is inefficient. This workflow automates the process: first finding the right files using metadata, then running a filtered vector search, so your queries always return the best-matching results from your uploads.\n\nThe workflow integrates Supabase and an AI chatbot to process, filter, and query text or PDF files. Steps include:\n\u2022 Searching file descriptions for initial filtering\n\u2022 Filtering file results by similarity threshold\n\u2022 Aggregating relevant file_ids for next-stage search\n\u2022 Running semantic (vector) queries only on those filtered files\n\u2022 Returning matched content with file names and URLs\n"
},
"typeVersion": 1
},
{
"id": "f49e8db9-244f-49e4-887a-2a5754f7c22c",
"name": "Sticky Note12",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1420,
340
],
"parameters": {
"color": 7,
"width": 330.5152611046425,
"height": 240.6839895136402,
"content": "### ... or watch set up video [15 min]\n[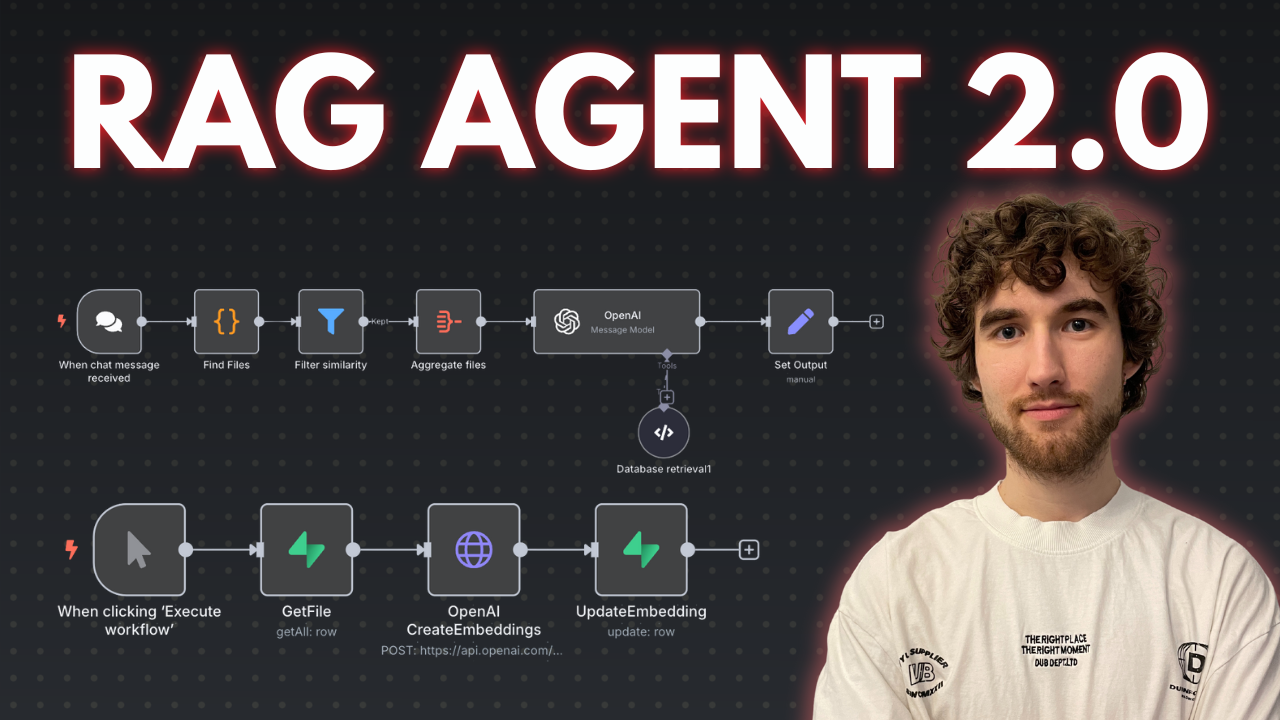](https://www.youtube.com/watch?v=asXVOHg89hs)\n"
},
"typeVersion": 1
}
],
"connections": {
"OpenAI": {
"main": [
[
{
"node": "Set Output",
"type": "main",
"index": 0
}
]
]
},
"GetFile": {
"main": [
[
{
"node": "OpenAI CreateEmbeddings",
"type": "main",
"index": 0
}
]
]
},
"Find Files": {
"main": [
[
{
"node": "Filter similarity",
"type": "main",
"index": 0
}
]
]
},
"Aggregate files": {
"main": [
[
{
"node": "OpenAI",
"type": "main",
"index": 0
}
]
]
},
"Filter similarity": {
"main": [
[
{
"node": "Aggregate files",
"type": "main",
"index": 0
}
]
]
},
"Database retrieval1": {
"ai_tool": [
[
{
"node": "OpenAI",
"type": "ai_tool",
"index": 0
}
]
]
},
"OpenAI CreateEmbeddings": {
"main": [
[
{
"node": "UpdateEmbedding",
"type": "main",
"index": 0
}
]
]
},
"When chat message received": {
"main": [
[
{
"node": "Find Files",
"type": "main",
"index": 0
}
]
]
},
"When clicking \u2018Execute workflow\u2019": {
"main": [
[
{
"node": "GetFile",
"type": "main",
"index": 0
}
]
]
}
}
}
Credentials you'll need
Each integration node will prompt for credentials when you import. We strip credential IDs before publishing — you'll add your own.
openAiApisupabaseApi
For the full experience including quality scoring and batch install features for each workflow upgrade to Pro
About this workflow
I prepared a comprehensive guide demonstrating how to build a multi-level retrieval AI agent in n8n that smartly narrows down search results first by file descriptions, then retrieves detailed vector data for improved relevance and answer quality.
Source: https://n8n.io/workflows/5436/ — original creator credit. Request a take-down →
Related workflows
Workflows that share integrations, category, or trigger type with this one. All free to copy and import.
This workflow is for: People who want to quickly launch simple landing pages without paying monthly fees to landing page creators. It’s ideal for rapid prototyping, generation of large amounts of land
Automate the creation of high-performing YouTube Shorts in minutes! Content Creators: Generate engaging short videos effortlessly. Marketing Agencies: Produce client-ready content quickly. Business Ow
🚨 LinkedIn search is BROKEN.
This n8n template demonstrates how to turn raw YouTube comments into research-backed content ideas complete with hooks and outlines.
Make OpenAI Citation for File Retrieval RAG. Uses memoryBufferWindow, stickyNote, chatTrigger, openAi. Chat trigger; 19 nodes.