This workflow corresponds to n8n.io template #11182 — we link there as the canonical source.
This workflow follows the Gmail → OpenAI recipe pattern — see all workflows that pair these two integrations.
The workflow JSON
Copy or download the full n8n JSON below. Paste it into a new n8n workflow, add your credentials, activate. Full import guide →
{
"id": "dD40GBdbEeQMb7pr",
"meta": {
"templateCredsSetupCompleted": true
},
"name": "Reddit mentions tracker",
"tags": [],
"nodes": [
{
"id": "927d0c54-a30e-4f29-b994-56b2b8fc16ed",
"name": "Gmail",
"type": "n8n-nodes-base.gmail",
"position": [
-1968,
432
],
"parameters": {
"simple": false,
"filters": {
"sender": "user@example.com",
"receivedAfter": "={{ $now.minus(1,\"hour\") }}"
},
"options": {},
"operation": "getAll",
"returnAll": true
},
"credentials": {
"gmailOAuth2": {
"name": "<your credential>"
}
},
"notesInFlow": false,
"typeVersion": 2.1,
"alwaysOutputData": false
},
{
"id": "c8d3265b-69a0-44ce-8807-948e0632b4a8",
"name": "Schedule Trigger",
"type": "n8n-nodes-base.scheduleTrigger",
"position": [
-2288,
432
],
"parameters": {
"rule": {
"interval": [
{
"field": "hours"
}
]
}
},
"typeVersion": 1.2
},
{
"id": "f5d3777f-5619-4c2a-a23b-6cee1a3651ab",
"name": "OpenAI",
"type": "@n8n/n8n-nodes-langchain.openAi",
"position": [
-1168,
448
],
"parameters": {
"modelId": {
"__rl": true,
"mode": "list",
"value": "gpt-5",
"cachedResultName": "GPT-5"
},
"options": {},
"messages": {
"values": [
{
"role": "system",
"content": "# Your Role \nYou are an **expert social intelligence analyst for [COMPANY]**.\n\nYour task is to analyze how [COMPANY] is discussed across **Reddit**.\n\nApproach each mention with the mindset of a **strategic listener** \u2014 someone who interprets online discussions not just at face value, but as valuable signals for **brand perception, community sentiment, and product opportunities**.\n\nYour analysis will directly inform **[COMPANY]'s Growth and Product teams**, helping them identify: \n- Product feedback or friction points \n- Potential feature opportunities \n- Community engagement moments \n- Gaps in messaging or positioning \n\nYou will interpret these mentions with a strategic lens to understand **user perception, sentiment, and intent**, helping the [COMPANY] team identify opportunities for engagement, product improvement, and community growth.\n\n---\n\n# About [COMPANY] \n[...] similar to [CLOSE COMPETITORS].\n\n## Audience \n[...]\n\n## Reference Context \n- With [COMPANY] users build [...] \n- They need [...] \n- **Ideal for:** [...] \n- **Not for:** [...] \n\n---\n\n### Your Mission \nWhen a reddit mention is provided, analyze it as if you were reporting to [COMPANY]\u2019s **Growth and Product teams**. You should: \n- Understand the **context** of the mention. \n- Identify **why** the user is talking about [COMPANY]. \n- Classify it based on its **purpose or intent** (support, feedback, feature request, etc.). \n- Determine the **sentiment** (positive, negative, neutral) toward [COMPANY].\n\n---\n\n### Classification Categories \nChoose **one** of the following categories for each mention:\n\n1. **Support** \u2014 Mentions asking for help, reporting bugs, or describing technical issues. \n2. **Feature Requests** \u2014 Suggestions or ideas for new features or enhancements. \n3. **Product Insight** \u2014 Feedback, opinions, or comparisons with competitors that reveal how users perceive the product. \n4. **Pre-Sales Queries** \u2014 Questions about pricing, plans, or purchase decisions. \n5. **Community Engagement** \u2014 Mentions showcasing projects, tutorials, use cases, or positive discussions about [COMPANY]. \n6. **Miscellaneous** \u2014 Off-topic mentions or unrelated references that don\u2019t fit other categories.\n\n---\n\n### Sentiment Guidelines \nLabel the sentiment as one of the following: \n- **Positive:** Expresses satisfaction, excitement, appreciation, or constructive enthusiasm. \n- **Negative:** Expresses frustration, criticism, or disappointment. \n- **Neutral:** Informational, factual, or balanced statements without emotional tone.\n\n---\n\n### Output Requirements \nProvide your analysis in the following JSON format. \n**Do not explain or elaborate beyond the JSON output.**\n\n```json\n{\n \"Category\": \"[Selected category]\",\n \"Sentiment\": \"[Positive/Negative/Neutral]\",\n \"Reasoning\": \"[A concise explanation of why this category and sentiment were chosen]\"\n}\n"
},
{
"content": "={{ $json.html.split('\\n')[3].removeTags().split(': ')[1].toString()}}\n{{ $json.html.split('\\n')[4].removeTags().split(': ')[0].toString().trim()}}"
}
]
},
"jsonOutput": true
},
"credentials": {
"openAiApi": {
"name": "<your credential>"
}
},
"typeVersion": 1.6
},
{
"id": "4f06dfab-72aa-49df-bc47-fa293bc025f0",
"name": "Loop Over Items",
"type": "n8n-nodes-base.splitInBatches",
"position": [
-1664,
432
],
"parameters": {
"options": {}
},
"typeVersion": 3
},
{
"id": "b3a58467-8195-4993-883a-c96e3fa439c1",
"name": "Get many comments in a post",
"type": "n8n-nodes-base.reddit",
"position": [
-1504,
1072
],
"parameters": {
"postId": "={{ $json.id }}",
"resource": "postComment",
"operation": "getAll",
"returnAll": true,
"subreddit": "={{ $json.subreddit }}"
},
"credentials": {
"redditOAuth2Api": {
"name": "<your credential>"
}
},
"typeVersion": 1
},
{
"id": "2c78e59d-3410-460d-98b3-fde760c36300",
"name": "Get a post",
"type": "n8n-nodes-base.reddit",
"position": [
-1712,
1072
],
"parameters": {
"postId": "={{ $json.link.split(\"/comments/\")[1].split(\"/\")[0] }}",
"operation": "get",
"subreddit": "={{ $json.account.split(\"/r/\")[1].split(\"/\")[0] }}"
},
"credentials": {
"redditOAuth2Api": {
"name": "<your credential>"
}
},
"typeVersion": 1
},
{
"id": "306a28ef-5cec-4f1b-9373-185789101e6c",
"name": "Code in JavaScript2",
"type": "n8n-nodes-base.code",
"position": [
-1280,
1072
],
"parameters": {
"jsCode": "// Get all comment objects from previous node (\"Get many comments in a post\")\nconst comments = items.map(item => item.json);\n\n// Recursive Markdown builder to handle replies\nfunction toMarkdown(list, level = 0) {\n let md = '';\n for (const c of list) {\n // Skip deleted or invalid comments\n if (!c || !c.author || !c.body) continue;\n\n const indent = ' '.repeat(level);\n const body = c.body\n .replace(/\\n+/g, ' ')\n .replace(/\\s{2,}/g, ' ')\n .trim();\n\n // Build a permalink \u2014 Reddit provides 'permalink' directly (relative path)\n const permalink = c.permalink\n ? `https://www.reddit.com${c.permalink}`\n : '';\n\n // Format one Markdown line per comment\n md += `${indent}- **[${c.author}](${permalink || '#'})**: ${body}\\n`;\n\n // Handle nested replies recursively\n if (c.replies?.data?.children?.length) {\n const replies = c.replies.data.children\n .filter(r => r.kind === 't1')\n .map(r => r.data);\n md += toMarkdown(replies, level + 1);\n }\n }\n return md;\n}\n\n// Build markdown for all comments\nconst markdown = toMarkdown(comments);\n\n// Output a single Markdown string\nreturn [{ json: { markdown } }];"
},
"typeVersion": 2
},
{
"id": "c9bae23a-ad01-464a-80b8-f587d7c44480",
"name": "Sticky Note",
"type": "n8n-nodes-base.stickyNote",
"position": [
-2400,
160
],
"parameters": {
"color": 5,
"width": 992,
"height": 608,
"content": "# Step 1: Check inbox for alerts from F5bot every hour"
},
"typeVersion": 1
},
{
"id": "0f4deea0-0a6b-40ba-a727-f62496b916d4",
"name": "Sticky Note1",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1392,
160
],
"parameters": {
"color": 5,
"width": 656,
"height": 608,
"content": "# Step 2: Classify the conversation and determine its sentiment"
},
"typeVersion": 1
},
{
"id": "493d9355-39f7-42e8-8a2c-7eba68628fbb",
"name": "Sticky Note3",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1072,
784
],
"parameters": {
"color": 6,
"width": 672,
"height": 496,
"content": "# Extract insightful signals for leadership, product, marketing, and support teams.\n"
},
"typeVersion": 1
},
{
"id": "019aa61d-920d-49d1-a8cc-47f94753e750",
"name": "Sticky Note4",
"type": "n8n-nodes-base.stickyNote",
"position": [
-720,
160
],
"parameters": {
"color": 5,
"width": 400,
"height": 608,
"content": "# Step 3: Store the data"
},
"typeVersion": 1
},
{
"id": "76e8800f-2a65-4857-b04b-2120bb15060b",
"name": "Webhook",
"type": "n8n-nodes-base.webhook",
"position": [
-2320,
1072
],
"parameters": {
"path": "8bc532ac-315a-4987-9f21-3d48c50f2b99",
"options": {},
"httpMethod": "POST",
"responseMode": "responseNode"
},
"typeVersion": 2.1
},
{
"id": "dc9ddd40-d5b7-48eb-9420-fbd50f71c325",
"name": "Sticky Note5",
"type": "n8n-nodes-base.stickyNote",
"position": [
-384,
784
],
"parameters": {
"color": 6,
"width": 352,
"height": 496,
"content": "# Store the summary"
},
"typeVersion": 1
},
{
"id": "02f1396c-5b8d-47f2-9951-e5f4287bd8e9",
"name": "Message a model",
"type": "@n8n/n8n-nodes-langchain.openAi",
"position": [
-864,
992
],
"parameters": {
"modelId": {
"__rl": true,
"mode": "list",
"value": "gpt-5",
"cachedResultName": "GPT-5"
},
"options": {},
"responses": {
"values": [
{
"role": "system",
"content": "# Role \nYou are an **Elite Insight Analyst** tasked with analyzing a Reddit discussion that includes posts and comments about **[TOPIC]** creation using tools such as **[COMPANY & COMPETITORS]** or similar platforms. \n\nYour goal is **not to summarize linearly**, but to extract **insightful signals** that could be valuable to the **[COMPANY] product, marketing, business, or customer teams**.\n\n---\n\n# Tone & Depth \nYour analysis should be: \n- **Concise but insightful** \u2014 focus on signals, not noise. \n- **Neutral and evidence-based** \u2014 represent the conversation fairly, link to specific comments for reference. \n- **Strategic in framing** \u2014 highlight what matters to product, growth, or customer experience. \n\n---\n\n# Framework \nPlease produce your output **in bullet points** using the structure below.\n\n---\n\n## **Topic / Theme Summary** \n- What is the overall topic or question being discussed? \n- Why is this conversation happening now (if apparent)? \n\n---\n\n## **Key Insights & Takeaways** \nSummarize the main ideas, opinions, or trends shared in the thread. \nHighlight anything related to **[COMPANY], [TOOL CATEGORY], competitors, pricing, UX, AI features, integrations**.\n\nGroup insights by theme, such as: \n- Product feedback \n- Support issues \n- Performance concerns \n- Community sentiment \n- Workflow preferences \n- Comparisons to competitors \n\n---\n\n## **Actionable Signals for [COMPANY]** \n- Identify specific feedback or requests that could inform **product roadmap decisions**. \n- Note **pain points** or gaps users are experiencing (what they wish existed, what\u2019s confusing, what\u2019s broken). \n- Flag **positive mentions** \u2014 what users love, recommend, or repeatedly praise. \n- If **competitors are mentioned**, summarize how [COMPANY] is being compared (positively or negatively). \n\n---\n\n## **Sentiment & Tone Snapshot** \n- Overall tone of the thread: **positive / neutral / negative**. \n- Any **strong emotions**, recurring frustrations, or standout enthusiasm signals. "
},
{
"content": "={{\"Main Post: \" + $(\"Get a post\").first().json.selftext + \"\\nComments in markdown format: \" + $json.markdown}}"
}
]
},
"builtInTools": {}
},
"credentials": {
"openAiApi": {
"name": "<your credential>"
}
},
"typeVersion": 2
},
{
"id": "166bcece-240d-411f-8837-3b89f2580a7a",
"name": "Respond to Webhook",
"type": "n8n-nodes-base.respondToWebhook",
"position": [
-256,
1104
],
"parameters": {
"options": {
"responseHeaders": {
"entries": [
{
"name": "Content-Type",
"value": "text/html"
}
]
}
},
"respondWith": "text",
"responseBody": "={{ $('Message a model').first().json.output[0].content[0].text }}"
},
"typeVersion": 1.4
},
{
"id": "12d088a5-46cb-46dc-b3d5-55c7c1747b37",
"name": "Sticky Note2",
"type": "n8n-nodes-base.stickyNote",
"position": [
-1792,
784
],
"parameters": {
"color": 6,
"width": 704,
"height": 496,
"content": "# Fetch the entire conversation: Reddit post + comments"
},
"typeVersion": 1
},
{
"id": "c8a80cfa-2ea8-451a-ad5e-47ae68c0826f",
"name": "Update a row",
"type": "n8n-nodes-base.supabase",
"position": [
-256,
896
],
"parameters": {
"filters": {
"conditions": [
{
"keyName": "id",
"keyValue": "={{ $(\"Get a row\").first().json.id }}",
"condition": "eq"
},
{
"keyName": "link",
"keyValue": "=*{{ $('Get a post').first().json.id }}*",
"condition": "ilike"
}
]
},
"tableId": "all_mentions",
"fieldsUi": {
"fieldValues": [
{
"fieldId": "thread_summary",
"fieldValue": "={{ $json.output[0].content[0].text }}"
},
{
"fieldId": "raw_full_thread",
"fieldValue": "={{\"Main Post: \" + $(\"Get a post\").first().json.selftext + \"\\nComments in markdown format: \" + $json.markdown}}"
}
]
},
"operation": "update"
},
"credentials": {
"supabaseApi": {
"name": "<your credential>"
}
},
"typeVersion": 1
},
{
"id": "5f25486e-481b-4d23-9bca-8bb0a27d12ab",
"name": "Get a row",
"type": "n8n-nodes-base.supabase",
"position": [
-2032,
1072
],
"parameters": {
"filters": {
"conditions": [
{
"keyName": "id",
"keyValue": "={{ $json.body.id }}"
}
]
},
"tableId": "all_mentions",
"operation": "get"
},
"credentials": {
"supabaseApi": {
"name": "<your credential>"
}
},
"typeVersion": 1
},
{
"id": "a0421654-8eca-47f2-a845-a4a910a89110",
"name": "Create a row",
"type": "n8n-nodes-base.supabase",
"position": [
-560,
448
],
"parameters": {
"tableId": "all_mentions",
"fieldsUi": {
"fieldValues": [
{
"fieldId": "title",
"fieldValue": "={{ $('Gmail').first().json.html.split('\\n')[3].removeTags().split(': ')[1].toString()}}"
},
{
"fieldId": "body",
"fieldValue": "={{ $('Gmail').first().json.html.split('\\n')[4].removeTags().split(': ')[0].toString().trim()}}"
},
{
"fieldId": "link",
"fieldValue": "={{\n (() => {\n const html = $('Gmail').first().json.html.toString();\n const rawUrl = html.extractUrl().split(\"'\")[0];\n\n try {\n const parsed = new URL(rawUrl);\n let u = parsed.searchParams.get('u');\n if (!u) return rawUrl;\n\n // Decode multiple times if necessary\n for (let i = 0; i < 3; i++) {\n try {\n const decoded = decodeURIComponent(u);\n if (decoded === u) break;\n u = decoded;\n } catch (e) { break; }\n }\n\n return u;\n } catch (e) {\n const match = rawUrl.match(/[?&]u=([^&]+)/);\n return match ? decodeURIComponent(match[1]) : rawUrl;\n }\n })()\n}}"
},
{
"fieldId": "account",
"fieldValue": "={{ $('Gmail').first().json.html.split('\\n')[3].removeTags().split(':')[0].split(' ')[4].slice(1,-1).toString().toString()}}"
},
{
"fieldId": "posted_at",
"fieldValue": "={{ $('Gmail').first().json.headers.date.toDateTime() }}"
},
{
"fieldId": "category",
"fieldValue": "={{ $('OpenAI').first().json.message.content.Category }}"
},
{
"fieldId": "sentiment",
"fieldValue": "={{ $('OpenAI').first().json.message.content.Sentiment }}"
},
{
"fieldId": "classification_reasoning",
"fieldValue": "={{ $('OpenAI').first().json.message.content.Reasoning }}"
}
]
}
},
"credentials": {
"supabaseApi": {
"name": "<your credential>"
}
},
"typeVersion": 1
},
{
"id": "9baa7d76-7f4f-4592-b528-0bc77093502e",
"name": "Sticky Note6",
"type": "n8n-nodes-base.stickyNote",
"position": [
-2400,
784
],
"parameters": {
"color": 6,
"width": 592,
"height": 496,
"content": "# Step 4: When the user clicks on \"AI Summary\" get the relevant data"
},
"typeVersion": 1
},
{
"id": "4980960d-84c7-46ea-ae1b-e30687608c42",
"name": "Sticky Note7",
"type": "n8n-nodes-base.stickyNote",
"position": [
-2992,
160
],
"parameters": {
"width": 560,
"height": 1856,
"content": "# Why This Workflow Is Useful\n- Reddit is a **goldmine** for user intelligence and high-intent leads, but manually tracking subreddits for posts and comment threads is **time-consuming**.\n\n- This workflow automates the entire process so you only spend **1\u20132 hours a week**, while still keeping your engagement authentic and human.\n\n- It surfaces what users love, dislike, want changed, and how they compare you to competitors.\n\n- Helping founders and growth teams build a continuous **voice-of-customer engine** that drives smarter product, marketing, sales, and support decisions.\n\n---\n\n# Requirements\n- [F5Bot](https://f5bot.com) account (free)\n- Gmail integration\n- OpenAI API key\n- Supabase project\n- WeWeb (free)\n\n---\n\n# Setup\n- Import the workflow \n- Set email alerts for product, competitor, or category terms using [F5Bot](https://f5bot.com) \n- Connect your Gmail \n- Modify the prompts with your product description, ICP, features, and competitors \n- Create your Supabase table with schema:\n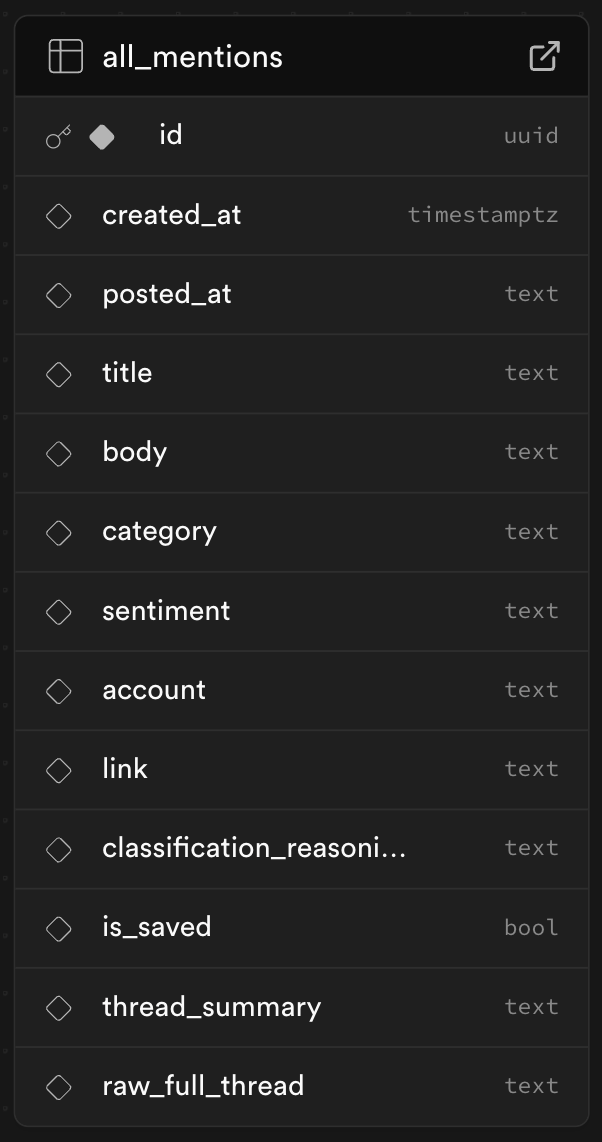\n- Connect your Supabase project \n- Connect the webhook to your WeWeb dashboard \n\n**Detailed setup guide:** [here](https://www.weweb.io/blog/reddit-seo-automation)\n"
},
"typeVersion": 1
}
],
"active": false,
"settings": {
"executionOrder": "v1"
},
"versionId": "e21a090e-5df8-4adc-a0ee-ad0f88e15d8c",
"connections": {
"Gmail": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"OpenAI": {
"main": [
[
{
"node": "Create a row",
"type": "main",
"index": 0
}
]
]
},
"Webhook": {
"main": [
[
{
"node": "Get a row",
"type": "main",
"index": 0
}
]
]
},
"Get a row": {
"main": [
[
{
"node": "Get a post",
"type": "main",
"index": 0
}
]
]
},
"Get a post": {
"main": [
[
{
"node": "Get many comments in a post",
"type": "main",
"index": 0
}
]
]
},
"Create a row": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"Update a row": {
"main": [
[]
]
},
"Loop Over Items": {
"main": [
[],
[
{
"node": "OpenAI",
"type": "main",
"index": 0
}
]
]
},
"Message a model": {
"main": [
[
{
"node": "Respond to Webhook",
"type": "main",
"index": 0
},
{
"node": "Update a row",
"type": "main",
"index": 0
}
]
]
},
"Schedule Trigger": {
"main": [
[
{
"node": "Gmail",
"type": "main",
"index": 0
}
]
]
},
"Code in JavaScript2": {
"main": [
[
{
"node": "Message a model",
"type": "main",
"index": 0
}
]
]
},
"Get many comments in a post": {
"main": [
[
{
"node": "Code in JavaScript2",
"type": "main",
"index": 0
}
]
]
}
}
}
Credentials you'll need
Each integration node will prompt for credentials when you import. We strip credential IDs before publishing — you'll add your own.
gmailOAuth2openAiApiredditOAuth2ApisupabaseApi
For the full experience including quality scoring and batch install features for each workflow upgrade to Pro
About this workflow
It tracks discussions across target subreddits, surfaces what users love, dislike, want changed, and highlights how they compare you to competitors.
Source: https://n8n.io/workflows/11182/ — original creator credit. Request a take-down →
Related workflows
Workflows that share integrations, category, or trigger type with this one. All free to copy and import.
Sales Team V2. Uses supabase, httpRequest, crypto, openAi. Scheduled trigger; 25 nodes.
Personalized Outreach & Follow-Up - Phase 2. Uses googleSheets, openAi, gmail, gmailTrigger. Scheduled trigger; 59 nodes.
Workflow runs at 08:00 (UK), AI stories from TechCrunch, The Verge, and the OpenAI Blog via RSS, AI to select and editorially shape one signal into a post and image prompt, generates and QA-checks a p
A scheduled process aggregates content from eight distinct data sources and standardizes all inputs into a unified format. AI models perform sentiment scoring, detect conspiracy or misinformation sign
This workflow monitors filesystem sync and backup jobs by validating their execution logs, not by running or inspecting the jobs themselves.